|
二、文学实验室的研究成果 2010年,莫莱蒂与马修·乔克思(Matthew L. Jockers)一起共同建立了文学实验室,尝试用科学研究中的协同合作方式来开展文学研究。在传统的文学研究模式里,“一个有资格(如获得博士学位,或正在攻读博士学位)的作者”产生了一个原创性的想法,将其应用到一个文本或一些问题上,然后完全依靠个人的力量生产出一个新的文本。[19]但文学实验室却创立了一个类似科学实验室的环境,“一种让个体退到背景,让实验本身移到前景的工作方式”。[20]在第一篇集体合作的研究论文遭到学术期刊的婉拒之后,莫莱蒂和实验室成员决定以“小册子”(pamphlet)的形式,将研究成果公开发表在实验室的网站上。目前,实验室已经发布了12篇小册子,这里仅介绍莫莱蒂参与的三个集体研究项目。 (一)词语与文类识别 2011年,莫莱蒂与博士生艾莉森(SarahAllison)等人合作发布了实验室的第一个小册子《计量形式主义:一个实验》,探索了如何用计算机算法来为文学文本确定文类归属。[21]这项研究的缘起是,莎士比亚专家维特摩尔(Michael Witmore)向莫莱蒂介绍了他用Docuscope[22]识别莎士比亚戏剧类型的工作。为了了解同样的技术是否也能用来识别小说类型,莫莱蒂邀请维特摩尔来斯坦福做了一个文类配对实验。维特摩尔通过Docuscope技术只弄错了哥特小说和历史小说这两个文类,其他两组文类皆匹配成功。由于哥特小说和历史小说的文类边界本来就不甚清晰,这个结果可说是相当不错。随后,乔克思也尝试用一个包含44个单词和标点符号的特征集(featureset)来识别文类,结果和Docuscope的成绩一样好。这些词后来被实验室命名为“最常见词语”(Most Frequent Words,简称MFW)。 计算机证实了文学研究者的一个普遍共识,即某些文本是可以归于同一个类型的,但计算机究竟是怎样分类的呢?维特摩尔向项目组成员展示了Docuscope分离出的一个最具哥特风格的文本字段。令人震惊的是,计算机识别的哥特风格特征与读者识别的特征完全不同。计算机捕捉到的是代词和过去时态,而读者则是通过文本中“被压制的恐惧”、“不安”、“废墟”、“颤抖的双腿”等词语判断出这是一部哥特小说。项目组成员意识到,文类如同楼房一样,在砂浆、砖块和建筑等每一个可能的分析尺度(scale)上都拥有一些独特的特征。MFW识别的是砂浆,Docuscope的词汇—语法范畴识别的是砖块,而读者识别的则是整个建筑。这三个层面没有任何交集,它们给出的文类标记也彼此不同。 然而,当项目组试图通过主成分分析[23]把文类系统从五花八门、互不相干的范畴[24]整合成由相互关联的形式变量构成的单一矩阵时,却遭遇到挫折。原因是文类是由风格标志和叙事标志(如情节)共同构成的,二者同等重要,而Docuscope和MFW主要是用来识别语言的。在缺乏识别情节的计算工具的情况下,文类识别的结果自然不可能准确。Docuscope和MFW实际上更适用于辨识同一个作者创作的不同文类的作品。因为一个作者即便创作出多种不同类型的作品,其语言风格也不会发生大的变化。这个持续了一年的研究项目虽然没有取得突破性的成果,但至少让莫莱蒂和团队成员迈出了实验性研究的第一步。 (二)句子与风格 2011年4月,实验室召开了一个年度工作总结会议。在会上,实验室成员再次讨论了第一个小册子《计量形式主义》,认为这项研究的真正对象也许是风格,句子则是风格的最基本单位,正是在句子层面,风格作为一种独特的现象获得了可见度。莫莱蒂随后和五名学生一起开展了一个关于小说句子的计算研究,并于2013年发表了实验室的第五篇小册子《句子尺度的风格》。[25] 项目组用Chadwyck-Healey19世纪小说数据库里的250部英国小说作为语料库,重点研究了叙事性句子。他们发现叙事性句子主要有三个类型:包含两个独立性从句(independent clause, 简称IC)的IC-IC类句子、一个独立性从句接一个非独立性从句(dependent clause,简称DC)的IC-DC类句子、以及一个非独立性从句接一个独立性从句的DC-IC类句子。通过从表达并列、转折、限定、顺序等多种逻辑-语义关系的连词入手,项目组注意到,IC-DC类句子主要涉及述谓和限定,较少涉及顺序。比如,P.B. 雪莱的一个句子:“Her extreme beauty softened the inquisitor who had spokenlast”(她极度的美貌软化了最后说话的审问者)。在这个句子里,非独立性从句一方面引出了一个不同于主句主语的新人物(审问者),同时又赋予了这个新人物在文本中极为有限的作用。从句自然地滑入了一种叙事性衰减。而在DC-IC类句子中,相反的情况出现了,位于主句之前的非独立性从句常常报告了一个准备性的事件,而主句则包含了更出人意料的事件。比如拉德克利夫的一个句子:“While she looked on him,his features changed and seemed convulsed in the agonies of death”(当她看着他,他的五官变了,似乎在死亡的痛苦里抽搐)。随着主语从“she”转为“his features”,叙事强度也增加了。也就是说,IC-DC类句子代表了叙事系统的收缩和衰减,DC-IC类句子则代表了扩张和强化。而在IC-IC类句子中,两个从句之间是重复或稍加解释的关系,叙事达到了一种静止状态。如狄更斯的一个句子:“Oh she looked very pretty,she looked very,very pretty!”(哦,她看上去非常漂亮,她看上去非常、非常漂亮!) 在发现了句子形式与逻辑关系和叙事节奏之间惊人的相关性之后,项目组又开始思考是否也能在句法和语义之间建立起某种联系。他们首先计算了所有句子中单词的平均(或称“预期”)出现频次,然后计算了这些单词在每一种句子类型中的实际出现频次,从而找出了那些显著高于预期的词语,也就是“最特别的词语”(Most Distinctive Words),最后又将这些数据用主成分分析方法视觉化。研究人员发现DC-IC类句子有一个稳定的模式,即它的非独立性从句中往往会包含一个空间运动,而它的独立性从句(或主句)则多和情感有关。比如,在“When the procession came to the grave the music ceased”(当队伍来到坟墓时,音乐停止了)这个句子里,独立性从句中先发生了一个空间运动(来到坟墓),然后才发生了其他的事情,空间运动成了叙事发展的跳板。而在“When the ceremony was over he blessed and embraced them all with tears of fatherly affection”(仪式结束后,他噙着饱含父爱的泪水,祝福和拥抱了所有人)这个句子里,主句中的叙事强化依靠的是情感,而非行动或事件。 施皮策(Leo Spitzer)和奥尔巴赫(Erich Auerbach)等文论家在讨论风格时,关注的都是段落和整个文本。莫莱蒂团队则通过研究从句的组合方式,提出了一个新的风格概念,将风格定义为“一个句子里各种分离的元素的浓缩(condensation)”,一种句法-语义性的浓缩过程。这种浓缩既是对某种规范的偏离,同时又是重复性的,通过一定量的重复形成了一种模式。风格从属于各种不确定的偶然性,它不是必然出现的。然而,当风格出现时,它会立即变得典型和可识别,能够以最直接和最不含糊的方式区分一个作者、一个文类、或一个文学运动。更重要的是,这个句子层面的风格概念是一个具有可操作性的概念,构成风格的元素是可以被计算机程序收集和测量的。[26] (三)文学经典的量化分析 数字人文方法到底给文学研究带来了哪些新的发现?当研究对象从经典转变为档案之后,会让文学研究有很大的改观吗?“经典”和“档案”这两个词到底意味着什么呢?实验室2016年发布的《经典/档案。文学场中的大规模动态》一文就旨在回答这些问题。[27] 莫莱蒂和项目组成员首先想到了布迪厄在《艺术的法则》一书中提供的一张关于19世纪末法国文学场的图。这张图根据成圣程度和经济效益两个指标展示了19世纪末各种文类和文学运动在文学场中的位置。尽管这张图影响力很大,但由于缺乏明确的、可测量的标准,它并没有真正成为一个可供其他学者复制的研究工具。为了对经典进行量化研究,项目组设计了两个可供量化的标准:人气(popularity)和声望(prestige)。人气的计算依据的是作家的作品在19世纪英国的重印次数和翻译成法语和德语的次数,声望则是依据作家在MLA(美国现代语言协会)参考文献数据库中被提及的次数,以及在DNB(《牛津国家人物大辞典》)中的词条的长度。根据这两个数据,项目组绘制出了一个18到19世纪英国小说场域图。这个小说场由三个部分构成(见图-3)。靠近纵轴的三角区域里的作家,其声望值比人气值至少高出两倍,靠近横轴的三角区域里的作家人气值比声望值至少高两倍。位于中间区域的作家,其声望值和人气值相互持平。我们熟知的19世纪英国经典作家大多位于中间区域,如笛福、理查逊、菲尔丁等。也就是说,布迪厄关于经典是“颠倒的经济世界”的观点并不准确。声望与人气并不必然对立,声望似乎就是从人气中发展出来的。通过把经典的概念分解为人气和声望(或市场和学院接受度)这两个基本要素之后,我们可以看到经典并不是一个具有自主性的概念,而是对立力量互动的随机结果。 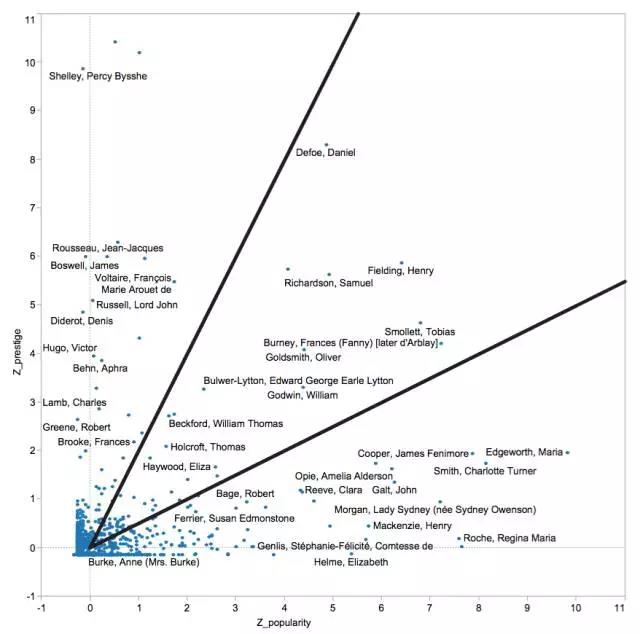 图-3 英国小说场(1770-1830),横轴代表人气,纵轴代表声望。 不过,项目组并不满足于像布迪厄那样进行文学社会学的研究,作为文学史研究者,他们还想知道小说的经典化过程是否和它们的形态特征有关。在项目的第二阶段,研究人员测量了语料库中的信息冗余程度。人们普遍认为读者偏好能提供丰富信息的文本,而不是有大量冗余信息的文本。因此,前一类文本会成为市场上的常青树,而后者则会被市场淘汰。一个二阶信息冗余(second order redundancy)的测试结果表明,[28]四分之三的经典文本所包含的冗余信息都比四分之三的档案文本(即非经典文本)要少得多。常识似乎是对的,经典文本的确包含了比档案文本更丰富的信息。为了验证这个结果,研究人员又使用了测量词汇丰富程度的语言学工具类符形符比。[29]如果一个文本的冗余性越低,那么它的词汇就应该越丰富。然而,测量的结果却令人困惑,经典文本从整个文本的词对(word pairs)的角度看,要比档案文本更丰富,但从单个词的角度看,经典文本比档案文本冗余性更强。奥斯汀、狄更斯、艾略特的作品的类符形符比都低于平均值。通过部分文本片段的细读,项目组发现,经典文本的冗余性与这些文本所描绘的创伤性事件、情感强度或口语形态(orality)有关,而类符形符比高的档案文本普遍体现出一种语言保守主义,喜爱用书面语,卖弄文藻,甚至还夹杂了来自其他文类的材料。比如,韦斯特(Jane West)就在她的作品里大量使用了诗歌、复杂的比喻和仿作(pastiche)。 在论文的结语部分,项目组对巴赫金小说理论的两个关键概念复调(polyphony)和杂语(heteroglossia)做出了修正。巴赫金认为复调和杂语是密切相关的,但项目组的研究结果却表明,复调和杂语实际上位于小说场中对立的区域。复调倾向于和经典文本联系在一起,而杂语则是那些失败的档案文本的特点。巴赫金认为,当小说与其他话语(discourse)发生接触时,小说会吸取那些话语的长处,从而强化自身在文化系统中的核心地位。然而,对历史、哲学、政论、旅行报道等其他话语的吸收,也可能产生负面影响,导致小说叙事活力的丧失。19世纪大量被遗忘的作家就是活生生的例子。因为当时英国小说形式的总体发展方向是“拧紧自己内在的叙事螺栓,而不是从外部话语寻找灵感”。[30] 尽管斯坦福文学实验室现已成为美国数字人文领域的重要机构之一,但莫莱蒂本人并不迷信数字人文。在他看来,数字人文不过是“数字时代针对文学和文化史的科学的、解释性的、经验性的、理性的……研究路径所采取的形式”。[31]数字人文研究目前仅仅提供了一个新的、比传统文学经典大得多的档案和新的、更快的计算程序,但它还缺乏新的概念,缺乏一个像什克洛夫斯基的《艺术作为技巧》、罗兰·巴特的《论拉辛》、或萨义德的《东方主义》那样的主要理论宣言。只有理论框架、阐释模式的变化才能让文学研究发生根本的变化。[32]如果数字人文做不到这一点,其价值就将始终存疑。 莫莱蒂尤其反对数字人文领域盛行的头脑简单的实证主义和数据驱动(data-driven)的研究方式。他援引库恩(Thomas Kuhn)的观点认为,仅仅通过检视数据,是不可能发现新的自然规律的。正确的做法应该是从理论出发,通过测量和数据,加强理论和现实之间的联系,把理论所蕴含的潜在(potential)秩序转换成实在(actual)秩序。理想的数字人文研究应是理论驱动的(theory-driven)、数据丰富的,不仅能够检验、证伪、挑战现存的文学研究知识,还能够创造出新的文学概念。[33]莫莱蒂和实验室成员通过计算研究对奥尔巴赫、巴赫金、布尔迪厄等权威学者所提出的文学理论的验证和修订,他们将“经典”、“风格”等模糊的文学概念变得可操作、可计量的努力,都是在朝着这个理想迈进。 (责任编辑:admin) |