|
摘 要:弗朗哥·莫莱蒂是美国当代知名的文学教授,在文学史、比较文学和数字人文等领域都做出了重要贡献。本文围绕莫莱蒂提出的远读概念及其所创立的文学实验室,介绍了他利用定量和计算方法从事文学研究的主要思路和成果。莫莱蒂的研究路径或可为当下中国学界的一些争议和困惑提供别样的思路;他不断将自然科学、社会科学的理论和方法融入文学研究的努力,也值得国内学者借鉴和效法。 关键词:弗朗哥·莫莱蒂、远读、文学实验室、数字人文、文学研究 作者简介:杨玲,厦门大学中文系助理教授,主要从事媒介与文化研究、西方文论研究。已出版专著《转型时代的娱乐狂欢——超女粉丝与大众文化消费》(2012),编著《粉丝文化读本》(2009)、《名人文化研究读本》(2013)、Boys’ Love, Cosplay, and Androgynous Idols:Queer Fan Cultures in Mainland China, Hong Kong, and Taiwan (2017),并在Cultural Studies,International Journal of Cultural Studies,《文艺研究》、《文化研究》等中英文刊物上发表过多篇学术论文。 弗朗哥·莫莱蒂(Franco Moretti)是斯坦福大学英语和比较文学的讲席教授,并创立了斯坦福文学实验室(Standford Literary Lab)。2014年3月,他的论文集《远读》(Distant Reading)因“提出了大胆而不同寻常的文学研究方法”获得美国“全国图书评论界批评奖”。[1]截止2016年,莫莱蒂已出版了七部英文专著,并主编了一部关于小说的百科全书《小说》(The Novel),在文学史、比较文学和数字人文等领域都做出了重要贡献。国内目前虽然已出现了多篇关于莫莱蒂的论文,[2]但尚未有人关注到文学实验室的运作情况,部分绍介还存在一定的误译和误读。[3]本文以莫莱蒂及其团队的学术发表为基础,结合相关书评、讨论和访谈,介绍了他利用定量(quantitative)和计算(computational)方法从事文学研究的主要思路和成果,并探讨了这些方法对于中国文学研究的启示。 一、“远读”的方法与实践 莫莱蒂的文学研究有其独特的内在理路。由于大学期间深受意大利马克思主义哲学家德拉沃尔佩(Galvano Della Volpe)的影响,他一直对科学精神充满敬重,[4]并且从1980年代后期就开始探讨文学中的进化理论。莫莱蒂最初只是对文学形式的历史变化过程感兴趣,后来受著名进化生物学家恩斯特·迈尔(Ernst Mayr)的种形成(speciation)理论的启发,注意到地理在新形式的生成过程中的作用,因而转向制图学,开始制作文学地图,并在1990年代末出版了专著《欧洲小说地图集1800—1900》。[5]在从事文学地理学研究时,莫莱蒂意识到定量方法对地图制作的作用,又开始对计量史学产生了浓厚兴趣,并因此形成了“远读”的初步设想。[6] 在2000年发表的《关于世界文学的猜想》一文中,莫莱蒂不仅提出了著名的“世界文学体系”的假说,还同时提出了“远读”的概念。国内学者多关注前者,而忽略了后者。这两个概念其实是相辅相成的:前者重新规划了文学史的研究对象,后者则是针对新的研究对象所采用的研究方法。莫莱蒂认为,存在着一个可被划分为中心和边缘的、不平等的世界文学体系。我们无法用传统的细读(closereading,也可译作“近读”)方法来研究这一体系,因为细读是一种“神学操练”,它以极其严肃的态度对待极少量的文本,导致大量的文学作品从未被研究者阅读。如果想要理解“整个体系”,就必须采取远读的方法,聚焦“比文本小很多或大很多的单位:手法、主题、修辞——或文类和体系”。[7] (一)小说的跨国兴起与文类周期 在2005年出版的《图表、地图和树:文学史的抽象模型》[8]一书中,莫莱蒂用三篇分别借鉴了年鉴派史学、地理学和进化论的论文,示范了远读的操作方法,并以此来说明远读关注的是“形状、关系、结构”以及“形式”和“模型”,距离不是障碍,而是“一种特定的知识形式”。[9]该书的第一篇论文《图表》已经初步运用了定量的研究方法。莫莱蒂在文中开门见山地重申了他对经典的怀疑,200部经典小说对于十九世纪的英国来说似乎已经够多了,但这个数字还不到英国19世纪出版的小说总量的1%。我们无法用阅读单个文本的方式来理解如此庞大的出版总量,“因为这是一个集体性的系统,必须用一种总体性的方式来把握”。[10]借助其他学者的统计数据,莫莱蒂首先用图表展示了英国、日本、意大利、西班牙和尼日利亚五国的小说发展史。从图中可以看出,五个国家都在不同的历史节点经历了类似的小说的兴起。在差不多20年的时间里,五国的小说出版量都出现了一个质的飞跃。莫莱蒂随后又用一些图表讨论了1740—1900年间英国小说类型的变化。通过查阅上百部研究资料,他整理出了一个包含44个小说文类的生存时间的图表(见图-1)。从图中可以看到,这些文类大多以聚类(cluster)的方式出现和消失,160年间共有六次创造力的大爆发,每个类型的存活时间差不多都是25年。 尽管莫莱蒂无法解释文类周期性变化的成因,但他还是从这次量化研究中获得了独特的发现。大部分文学史家都会把抽象的小说(the novel)和各种小说(亚)文类当作两个不同的东西,然而图-1中的44个文类却表明,小说不是作为一个单一的实体发展出来的,而是周期性地生成一整套类型。小说其实就是各种小说文类所构成的一个系统。在这个系统里,有些类型可能在形态上更加重要或更受欢迎,但它们绝对不是唯一存在的类型。当小说理论“将小说缩减为仅仅一个基本形式(现实主义小说、对话体小说、言情小说、元小说等等)”时,这就相当于把90%的文学史都抹杀掉了。[11]  图-1 英国小说类型(1740—1900) (二)小说标题的大数据解读 弗吉尼亚大学教授维尔蒙(Chad Wellmon)将莫莱蒂的远读定义为“通过用计算和定量的方法分析海量的文本来研究文学史中逐渐显现的和长期的模式(patterns)”。[12]然而直到2009年发表的《风格公司:对7000个标题的反思(英国小说,1740—1850)》一文,莫莱蒂才算是真正发挥了大数据分析的威力。在这篇论文里,莫莱蒂选取了1740到1850年间出版的7000部小说标题作为量化分析的对象。因为标题是“作为语言的小说与作为商品的小说的交汇点”。[13] 在论文的第一部分,莫莱蒂运用平均数、中值(也称“中位数”)和标准偏差三个统计学概念,测量了7000部小说标题的长度。他发现,在18世纪中期,小说标题还是长短不一,长的标题可以达到40个词甚至更多,但是到了19世纪中期,长标题就彻底消失了,小说的标题也变得越来越相似。莫莱蒂认为,小说标题的这一变化与图书市场的变化息息相关。首先由于市场上新出版的小说数量的激增,一些杂志开始刊登新书的评论,使得相当于小说内容梗概的长标题变得多余。其次,短标题比长标题更能迅速而有效地吸引公众的眼球,并被读者记住。三是当时主要的图书市场,也就是流通性图书馆往往在其目录上对长标题实行简化,使得读者日益习惯短标题。 论文的第二部分对短标题的内容进行了量化分析。莫莱蒂发现短标题主要包括三个类型:专有名词;冠词+名词;冠词+形容词+名词的组合。另外还有一个小类型,概念性抽象。在冠词+名词这个类型里,几乎一半的标题都描述的是一种带有异国情调或越轨色彩的人物类型,如The Vampyre(《吸血鬼》)。当一个形容词被加到这个组合里时,情况就颠倒过来了,法基尔人或浪荡子之流从50%降到了20%,而妻子和女儿却从16%上升到40%,如The Unfashionable Wife(《老土的妻子》)。莫莱蒂对此的解释是,如果标题里只有一个名词,该名词就必须保证一个有趣的故事,吸血鬼因而就成了一个好的选择。多了一个形容词之后,即便是熟悉的人物也会被陌生化,而且形容词为标题引入了一个具有叙事功能的述谓成分。关于专有名词的标题,莫莱蒂也有一个独特的发现,在1820、1830年之前,那些含有女性名字的小说标题大多只有名,没有姓。这意味着这些小说的女主人公都是需要丈夫的未婚女性,小说的内容也都是围绕结婚情节展开的。此后,标题中的女主人公名字大多都包含了姓氏,如Jane Eyre(《简爱》),结婚情节被嵌入了成长小说或工业小说,女性也开始从私人领域进入公共领域。那些包含抽象概念的标题也经历了一个引人注目的变化。在1776到1880年间,这些与伦理道德相关的标题大多强调的是对道德规则的违反,如Disobidence(《不服从》),但到了1800年之后,这些标题就开始强调道德的建构,如Self-Control(《自控》),这种对自我的规训暗示了维多利亚主义的萌芽。 (三)《哈姆莱特》的人物网络 在成功地运用量化文体学分析了小说的标题之后,莫莱蒂又在《网络理论,情节分析》一文中尝试用量化的方式来研究《哈姆莱特》的情节,因为他一直对哈姆雷特的朋友霍雷肖(Horatio)在剧中的作用感到困惑。然而,故事情节的量化远比莫莱蒂预想得困难,他不得不从定量研究退回到定性研究。尽管量化失败,但莫莱蒂还是借助网络理论[14]的基本概念,以视觉化的方式呈现了《哈姆莱特》中被忽略的人物和空间关系。复杂网络理论研究的是一大组对象之间的关系,这些对象被称为节点或顶点(nodesor vertices),它们可以是任何人或物,对象之间的联系被称为边(edges,也译作“连线”)。通过分析节点与边的连接方式,可以揭示大型系统的许多令人意想不到的特点。莫莱蒂将复杂网络理论移植到对叙事的分析,把《哈姆莱特》中的每一个人物定义为节点,只要两个人物之间说过话,就当作是一个边,根据这个方法生成了一个最基础的人物网络图。[15] 莫莱蒂认为,通过借助网络来思考情节,把叙事的时间转化为网络中的空间,可以有以下几个收获。首先,过去发生的事件与当下的事件一样获得了可见度。其次,整体情节中的某些特定“区域”(region)变得可见。比如,《哈姆莱特》中有一个死亡区域(见图-2中的标红区域),所有的死亡和悲剧都发生在这个以国王和王子为轴心的区域里。第三,人物网络是一个抽象的模型,它如同X光一样,可以让我们探测到隐藏在剧本背后的结构。如我们可以发现主人公其实就是网络的中心。哈姆莱特之所以是同名悲剧的主角,乃是因为他和剧中所有的人物都很近,平均只有1.45度的距离。第四,我们还可以利用这个模型来进行推演和实验,比如在网络图中抽出国王克劳狄斯,整个网络基本完好无损,抽出哈姆莱特,整个网络几乎分裂成两半,如果同时去掉哈姆莱特和霍雷肖,整个网络就彻底碎片化了,《哈姆莱特》也将不复存在。由此可见,主人公的重要性不在于其本身的特质,而在于他/她对网络的稳定性所起的作用。霍雷肖是剧中一个不可或缺的角色,因为他联系着绅士、水手、大使等一系列边缘人物,这些边缘人物指向的是丹麦京城艾尔西诺之外的世界,正处于萌芽状态的欧洲国家体系(state system)。霍雷肖这个没有动机、没有目的、没有情感、也没什么台词的扁平人物,其实就是官僚国家的象征。通过一系列的人物网络图,莫莱蒂对《哈姆莱特》做出了令人耳目一新的解读。 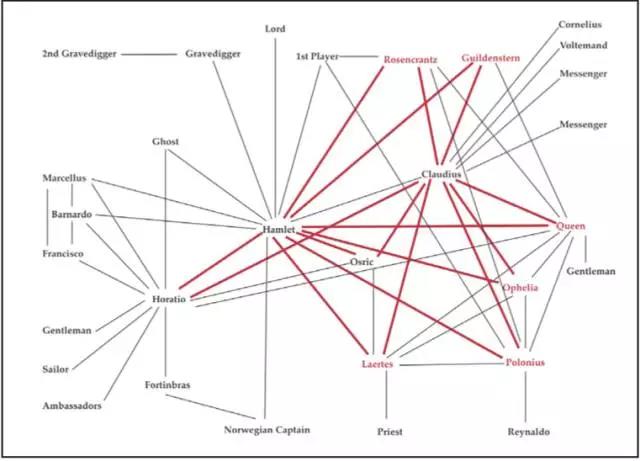 图-2 《哈姆莱特》的人物网络图,红色区域为死亡区域。 近年来,文本挖掘等数字人文技术的发展和认知科学关于阅读体验的新见解,对以文本细读为主的传统文学研究方法带来了前所未有的挑战,“如何阅读”这个本来不是问题的问题,开始变成了一个大问题。[16]莫莱蒂提出的远读概念,可谓是生逢其时。尽管远读算不上一个完整的理论体系,只是一些为了解决特定问题而设计的实验性方法,但它至少让人们看到文学研究除了细读,还可以有别的玩法。远读的这套方法也恰好顺应了欧美的数字人文风潮。[17]《图表、地图、树》和《远读》出版之后,都在学界引起热议,以至于莫莱蒂被称为“当今英文和比较文学领域最具争议性的人物”。[18] (责任编辑:admin) |