|
摘 要:多义词词典义项的可区分度是指,人们根据词典提供的信息在语料中对多义词义项进行辨析的难度。文章探讨如何度量多义词可区分度。以往对这个问题的研究主要使用两种方法:基于义类体系的方法和基于机器学习的词义消歧方法。文章提出利用人工标注词典义项,然后对标注结果计算标注者一致性(inter-annotators agreement)的方法,从而计算多义词义项可区分度。基于对几种方法的讨论和对比,文章发现,通过计算人工标注结果一致性的方法较为有效、直观和省力。文章认为,“多义词词典义项可分区度”是利用人对多义词辨析的结果,对词典义项的评价,并不必然反映词典释义的好坏,它应该被视为一类参考数据,为词典编纂提供指示。 关键词:多义词;义项可区分度;标注一致性;词义消歧 基金: 华东师范大学语文教育研究基地2020年度研究项目“部编本小学教材韵律词的切分及其分布研究”(项目编号12901-412224-19095/006)资助。 一、多义词词典义项的可区分度 在使用词典释义进行多义词辨析的过程中,多义词义项区别的难易程度是不同的,而这种难易程度不一定与词典释义有关。有的多义词义项比较难区分。如“包围”有两个义项[1]: (1) 包围1 四面围住: 亭子被茂密的松林包围着。 包围2 正面进攻的同时,向敌人的翼侧和后方进攻。 就词典释义来看,“包围”的两个义项不难区分。但在我们的实验中(将于下文第四节讨论),“包围”的词典义项可区分度仅为0.38。 又如,“暴雨”有两个义项: (2) 暴雨1 大而急的雨。 暴雨2 气象学上指1小时内雨量在16毫米以上,或24小时内雨量在50毫米以上的雨。 从词典释义上来看,“气象学上指1小时内雨量在16毫米以上,或24小时内雨量在50毫米以上的雨”应该是一种“大而急的雨”,难以区分。在我们的实验中,“暴雨”的可区分度为0.86。 我们把这种区别多义词词典义项的难易程度称为“可区分度”。从词义关系的角度看,多义词义项可区分度体现了义项在语义上的“重合”程度(肖航 2010),它是一种对词义关系的描写。尽管各家词典在多义词义项分立的标准和释义方法上多有不同,但是没有一部词典能够做到所有多义词都有等同的可区分度。这是因为,词典释义是“语言输入”,而可区分度是对多义词辨析结果——“语言输出”——的评价。从学习多义词词典释义到使用它在具体上下文中辨析词义的过程来看,从词典释义到义项可区分度过程如下: 1) 词典对多义词定义; 2) 用户学习词典释义,掌握多义词义项区别; 3) 在语料中进行多义词辨析; 4) 对辨析结果进行评价; 5) 得到义项可区分度。 根据上面的过程描述,可以发现,一方面,义项可区分度不是对多义词词典释义的直接评价,它从义项辨析结果中获得,反映词典释义对多义词辨析的有效性,即,人们学习了词典释义后,可以使用它有效地区分多义词义项;另一方面,作为“输出”的可区分度直接受到词典释义的影响,并反映词典释义可能存在的问题,为词典编纂提供参考性指示。义项的可区分度小,意味着人们对义项的区分有困难,词典编纂者可以对该多义词的释义进行检视。在积累了一些多义词义项可区分度数据后,词典编纂者可进一步对义项分立的原则和依据进行探讨。 我们认为,义项可区分度的形式应该是一个有限范围内的数值,所以无法通过理论探讨获得,必须在实证研究(empirical study)框架中,通过某种方法计算得到。 本文将讨论计算多义词词典义项可区分度的方法。现有的计算方法基本可以视为是对义项可区分度的简介描写。我们提出通过计算词义标注任务中的标注者一致性来估计义项的可区分度。本文内容安排如下: 第一节,提出我们对义项可区分度的定义;第二节,讨论已有的计算义项可区分度的方法,指出这些方法的缺陷;第三节,我们提出使用标注一致性估计可区分度;第四节,我们简单对比机器学习方法和标注者一致性方法的相关性;最后是结论和讨论。 二、计算义项可区分度的方法 计算义项可区分度,是要将可区分度以数值形式量化地表示,使得“可区分度”这一概念被直观地表示出来。词典义项是书面语构成的句子,无法被直接计算,所以首先需要将义项转换为可计算的表示方式。表示方式有两种,一种是将义项映射到一个词义分类体系中,然后通过计算义项在义类体系中的距离,以此代表可区分度;另一种是在大规模语料库中抽取义项的语言学特征,使用机器学习算法进行词义自动消歧(word sense disambiguation,以下简称WSD),用WSD的结果表示义项可区分度。这两种方法都需要比较大规模的语言资源,且各有利弊。 (一) 基于义类体系的方法 词的义类体系以词义的上下位关系为主线,将词义以义项为单位组织成树状结构。义类体系由根节点、中间节点、叶子节点和词义集合组成。根节点是义类体系的开头,衍生出若干下位节点(子节点);中间节点位于根节点和叶子节点之间,每个中间节点衍生自一个上位节点(父节点),并衍生出若干个下位节点;叶子节点是处于最下方的节点,每一个叶子节点衍生自一个上位节点,且不再衍生出下位节点;每个节点代表一个义类,每个义类对应一个词义集合,一个词义集合包含若干词义。基于义类体系的方法首先将多义词义项分配到义类树上(一个义项对应义类树的一个节点),然后计算义项在义类树上的距离,即,从一个节点到另一个节点需要经过多少步。距离越小,意味着义项在义类树上越接近,则越难区分——可区分度越低。最小的距离为0,这时义项对应义类树上的同一个义类节点。 该方法省时省力,不依赖词义标注语料库和复杂的计算方法,可以快速实现义项可区分度计算。(李安 2014) 然而,该方法的缺陷也很明显。 第一,该方法假设,在义类树上,节点到节点的距离是相等的,即,任意两个存在上下位关系的义类在语义上的差距是等同的(否则它就失去了通过计算义类节点相隔路径长度得到义项可区分度的基础),但实际上这个假设不成立。义类体系赖以建立的词义上下位关系只规定了词义的语义关系,并未对义类之间的这种语义关系的强弱做任何说明,义类体系也无法体现这一点。 第二,该方法依赖义类体系,而义类体系的建设存在随机性和主观性,且目前没有评价义类体系优劣的有效方法。构成义类树的基本词义关系是上下位关系,现实的义类体系则往往由多种词义关系和词义特征共同决定。比如,“同义词词林”至少包含了词义的相似关系和相关关系;“现代汉语词义分类体系”则纳入了词义在句法上实现的特征。另外,现有理论认为,义类划分应该尽可能避免跨类,认为分类应该是离散且互斥的,所以不同的学者对义类体系中义类的数量、定义以及具体词义应该纳入哪个义类,其意见是不统一的。比如,“锅”可以是“厨具类”,也可以是“容器类”。这样一来,义项在义类树上的距离会因为使用了不同的义类体系而不同。 第三,该方法要求先对多义词义项进行义类标注,即,将义项划分到义类树的一个义类上,这使得该方法在本质上是对义项词典释义进行比较,而非本文所定义的“义项可区分度”。 (二) 基于机器学习的词义消歧方法 词义消歧是在语料库中对多义词进行义项自动判别的工作。Ide和Veronis(1998)、吴云芳和俞士汶(2006)认为,传统词典在多义词定义方面缺乏一致性,义项间语义距离(称为“语义颗粒度”,semantic granuity)不等,使得对WSD结果难以准确评价。不过,这恰好可以为计算义项可区分度服务。既然WSD结果受词典定义影响,可以认为,语义距离大的义项,其消歧结果可能会比较好,其可区分度就比较大,反之,可区分度比较小。 该方法首先需要在语料库中标注多义词的词典义项,然后在语料库中抽取多义词义项的各种语言学特征,用这些特征构成向量来表示义项,通过计算义项向量的距离,来获得可区分度数值。 词义消歧的方法使用真实语料库,在消歧算法一致的前提下能够公正地评价义项可区分度,其优势在于尽可能地摆脱了主观性因素,使得计算结果较为客观。 当然,该方法亦有其缺陷。 第一,该方法假设,词典对义项的定义会充分反映在语料库中,所以从语料库抽取特征表示义项。但是,并不是所有的词义特征都会被显性地实现在语言中,尤其是语用义、修辞义。 第二,词义消歧依赖从语料库中获取的义项特征,而能够获取到什么样的特征,取决于语料库加工的深度和规模。如果语料库中没有语法标注,那么义项的语法特征是无法获得的。而制作大规模深加工语料库的时间和人力成本都非常高昂,获得难度比较大。所以,使用不同语料库得到的结果往往是不同的。这也证明了第一点的观点。 第三,该方法的结果需要在词汇学上得到解释。该方法是对义项可区分度的“间接估计”,本质上是用机器学习算法模拟人在真实语境中辨析多义词的行为。但算法与人在多义词判断的过程和方式上存在差异,所以通过词义消歧得到的义项可区分度数值需要在词汇学上得到解释,简单来说,就是要解决其在多大程度上可信的问题。 三、使用标注者一致性估计多义词义项的可区分度 根据上一节的论述,基于义类体系的方法和词义消歧的方法都不是对义项可区分度的直接度量,且在理论上有诸多缺点。本文提出使用标注者一致性的方法来估计多义词词典义项的可区分度。肖航(2010)做了一些尝试,利用标注者一致性来说明词典对多义词义项定义中存在的“重合”问题,指出,意义“重合”多的义项,标注者一致性更差。这说明,标注者一致性反映了人对词典释义的使用情况。 假设语料库中包含多义词W的词例数量为N,且W在词典中义项数量为I,标注者被要求对该多义词的每个词例标注合适的义项i(显然i属于I)。那么,那些标注者标注了相同义项标签的词例数量为A,标注了不同义项标签的词例数量为D(A与D之和为N)。可以用A除以N(A/N)获得标注者的简单一致性(simple agreement),其值越大,说明标注者一致性越高。不过,Veronis(1998)、Artstein和Poesio(2008)指出,简单一致性(A/N)存在标注者随意标注的问题,即,不排除标注结果是标注者随意标注的情况。比如,标注者对某个多义词标注了10条词例,且义项标记都是i,然后他/她对余下所有的词例义项都标注上i。为了消除简单一致性的这一缺陷,我们采用Cohen’s Kappa算法(Cohen 1960)来计算标注者一致性: 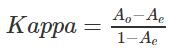 其中Ao是实际观察到的一致性,Ae是任意标注产生的一致性(也就是我们需要消除的那部分)。上式的大致意思是: 去除了由任意标注产生的一致性,才是准确的标注者一致性。Kappa值越高的多义词,其义项区分度越高。 标注者一致性是对义项可区分度的直接度量,因为它是对多义词辨析活动的直接观察。相较之下,词义消歧的结果是对可区分度的间接度量且需要语言学解释。所以,Kappa值更加“可信”。 四、义项可区分度结果分析 我们相信,多义词义项的可区分度值可以为词典编纂带来有益的信息。如前述“包围”的可区分度值提示了两个义项的定义可能存在难以区分的问题。这部分我们详述如何通过词义标注任务来获取义项可区分度,分析可区分度低于一定阈值的多义词,讨论低可区分度多义词词典义项定义的问题,以展示义项可区分度如何对词典编纂产生积极作用。 (一) 数据 我们从已标注了词典义项的“中小学教材语料库”中选取了419个包含两个义项的多义词,作为实验对象。在语料库中抽取到35068条包含所有实验对象的句子。 (二) 标注者一致性实验 标注者一致性实验及结果分析在(柏晓鹏 2020)[2]中有详细描述。我们选取了12位中文系语言学背景的本科生和研究生作为标注者,每条多义词例句由三位标注者标注,要求标注者每天最多标注1000条例句或最长连续工作60分钟,一共使用10天完成全部标注工作。这样,每一条多义词例句产生三个标注结果,可以有三个一致性Kappa值,我们取平均值作为可区分度数值: 平均Kappa值越高,则义项可区分度越大,反之义项可区分度越小。一般认为(Veronis 1998;Artstein & Poesio 2008),一致性结果中0.6和0.8是两个具有意义的值: 当Kappa值低于0.6的时候,可以认为一致性较差,在本文中表示义项可区分度较低;当Kappa值大于等于0.8的时候,一致性较好,表示义项可区分度较高。 (三) 可区分度低的多义词 在419个实验对象中,有229个多义词的义项可区分度低于0.6(54.7%)。这意味着在我们的实验对象中,有超过一半的多义词,其词典义项无法被很好地区分。通过分析可区分度低于0.6的多义词,我们发现,义项间有多种关系导致可区分度低下。 1. 义项释义存在重合关系。 有的多义词义项间存在一个义项可以被另一个义项包含的现象,如: (3) 奔(0.315) 奔走1 急走;跑: 奔走相告。 奔走2 为一定目的而到处活动: 奔走衣食│四处奔走│奔走了几天,事情仍然没有结果。 (4) 失败(0.56) 失败1 在斗争或竞赛中被对方打败(跟“胜利”相对): 非正义的战争注定是要失败的。 失败2 工作没有达到预定的目的(跟“成功”相对): 试验失败│失败是成功之母。 以上两个多义词,其义项内涵有“包含”关系,也就是肖航(2010)指出的义项“重合”关系。“为一定目的而到处活动”(奔走2)描述了人的活动,但可以包含“急走、跑”(奔走1)这样的具体动作行为。如: (5) ……一面要上书塾,一面要帮家务,天天奔走于当铺和药铺之间。 例(5)中的“奔走”做两种理解都可以,奔走1的词义内容被奔走2完全包含。 而“在斗争或竞赛中被对方打败”(失败1)也可视为“工作没有达到预定的目的”(失败2)的具体表现。 这种重合关系还体现在义项释义内容接近,有交叠,如: (6) 学(0.594) 学1 学习: 学技术│勤工俭学│我跟着他学了许多知识。 学2 模仿: 他学杜鹃叫,学得很像。 学1义为通过一种系统性的方式学习到一种有用技能,有“获取”义。学2描述这个行为本身,而不关注学习的对象和对象本身的价值。但可以认为在语义上,学2描述的是学1的一个阶段,二者释义内容有交叠: 人们总是通过模仿开始习得新的本领。如例(7): (7) 一只小鹰跟着老鹰学飞行。 例(7)中的“学”应选择哪个义项,与如何理解“小鹰”和“飞行”的关系有关: 如果认为“飞行”是一种技能,则应选学1;如果认为“小鹰学飞行”是一种来自于本能的行为,那选学2也不无道理。 2. 义项区别特征的实现问题。 词典释义中用以区分义项的语言学特征在语料中不实现,使得义项难以区分,如: (8) 贡献(0.594) 贡献1 拿出物资、力量、经验等献给国家或公众: 为祖国贡献自己的一切。 贡献2 对国家或公众所做的有益的事: 他们为国家做出了新的贡献。 “贡献”的两个义项,一个是名词义项,一个是动词义项,当出现在宾语位置上时(此时,词性得不到区分),义项的区分就发生问题了,如例(9): (9) 本来是可以不断再生,长期给人类做贡献的。 例(9)中“贡献”可以是贡献2,也可以看作是贡献1的动名词用法。 同样的例子还有: (10) 青年(0.591) 青年1 人十五六岁到三十岁左右的阶段: 青年人│青年时代。 青年2 指上述年龄的人: 新青年│好青年。 “青年”义项的释义是比较清晰的,二者的区分条件是: 青年1大部分时候出现在定语位置上,青年2大部分时候出现在中心语位置上。但我们观察到,在“青年男女”“青年农民”“青年画家”“青年朋友”“青年突击队员”等例子中产生了不一致,我们认为,这可能是因为青年2也可以出现在定语位置上的缘故。如: (11) 青年组织的队伍走过主席台…… 例(11)中的“青年”即为青年2。此时,区别两个义项的重要特征没有实现。 3. 搭配词有重合。 有些多义词义项依靠与之搭配词的词义得以区分,当搭配词有重合的时候,义项区分发生困难。 (12) 命运(0.333) 命运1 1. 指生死、贫富和一切遭遇(迷信的人认为是生来注定的): 悲惨的命运│命运不济。 命运2 比喻事物发展变化的趋向及结局: 关心国家的前途和命运。 根据释义,命运1是已经发生的事件的总和,命运2指称事物未来发展的可能性。而根据所举的例子,命运1指的是人的经历,命运2指的是社会组织(国家、集体等)的发展状态,“命运”的两个义项的差异主要通过定语位置上名词短语的语义来确定。命运2可以看作命运1的隐喻结果,除了指称对象发生明显变化外,两个义项在其他方面相似度较高,而“命运”在指称上的语义组合限制,即“生死、贫富和一切遭遇”或“发展变化趋势”,并不能通过前后几个词的搭配,在一个句子范围内得以实现,这使得两个义项定语位置上的搭配词有一定重合度,使得义项区分困难,如: (13) 这是每一个人的命运: 如果他达到注定的某一级…… (14) 因为欧洲的命运全系在拿破仑这一个人的命运。 例(13)中的“命运”应是命运1,但句子的后半部分“如果他达到注定的某一级”,又符合命运2的表述。例(14)中后一个“命运”应是命运1,因为指称“拿破仑”,但句子前半部分有“欧洲的命运”,而这两处“命运”应该是语义相同的。如此,导致“命运”的可区分度很低。 (四) 义项可区分度对词典编纂的启示 上文的工作显示,义项的可区分度提供了关于多义词的指向性信息,即,那些义项可区分度低于一定值的多义词义项需要进一步检视。通过上文第(三)部分中对一些义项可区分度小于0.6的词的分析,我们发现,造成多义词义项可区分度低原因可能是词典义项设置和释义不佳造成的,如例(3)、例(4)、例(6);有些则与释义无关,而与义项在语言中的具体实现有关,如例(8)、例(10)。所以,词典在释义方面可能需要注意义项在语义上的关系,并探讨是否需要在释义时考虑语法等表层实现的情况。 五、结论 本文对“多义词词典义项可区分度”这一概念进行了界定。我们认为,义项可区分度是通过对多义词辨析结果的评价,以此来评价多义词义项辨析难易程度的指标,其形式为有限范围内的数值。义项可区分度为词典编纂提供了参考信息: 义项可区分度低于阈值的多义词,编纂者可能需要对其定义进行检视。有利于词典编纂者有目的性地对词典进行修订。 我们讨论了当前计算义项可区分度的方法: 基于义类体系的方法和基于机器学习的词义消歧方法。基于义类体系的方法在理论上存在缺陷。基于机器学习的词义消歧方法是对义项可区分度的间接评价,其结果的准确性需要语言学解释的支撑。 我们进一步提出通过词义标注工作,计算标注者一致性数据来表示义项可区分度。这个方法基于多义词辨析活动的直接观察,是对义项辨识难度较为直接的测量,故具有比较好的可信度。同时需要指出,用标注者一致性来估计义项可区分度的方法依然会受到标注者的影响。主要是标注者人数、知识背景以及具体标注环境这几个方面。 我们今后的工作将集中在两个方面: 一是扩大标注者一致性实验的规模,对本文实验中可能存在的一些问题进行纠正;另一方面是尝试用词义消歧的方法来计算多义词义项可区分度,使用标注者一致性数据进行验证,以期找到一个合适的自动化工具。 参考文献 [1].李安.多义词义项的语义关系及其对词义消歧的影响.语言文字应用,2014(1). [2].肖航.词典多义词义项关系与词义区分.云南师范大学学报,2010(1). [3].吴云芳,俞士汶.信息处理用词语义项区分的原则和方法.语言文字应用,2006(2). [4].中国社会科学院语言研究所词典编辑室编.现代汉语词典(第7版).北京:商务印书馆,2016. [5].Artstein R,Poesio M.Inter-coder Agreement for Computational Linguistics.Computational Linguistics,2008,34(4). [6].Jacob Cohen.A Coefficient of Agreement for Nominal Scales.Educational and Psychological Measurement,1960,20(1). [7].Ide N,Veronis J.Word Sense Disambiguation:The State of the Art.Computational Linguistics,1998,24(1). [8].Veronis J.A Study of Polysemy Judgements and Inter-annotator Agreement.Programme and Advanced Papers of the Senseval Workshop.Herstmonceux,1998. 注释 1[1] 本文词典释义来自《现代汉语词典》第7版。 2[2] 柏晓鹏.利用标注者一致性数据估计多义词义项的区分度.世界汉语教学(待刊)。 (责任编辑:admin) |