|
表1中第一列是方言点名称,其余表示音系结构数据。每一个单元格的“0”表示单元格对应的方言点(行)不具备对应的特征(列),例如:文昌在特征“p”上显示为0,表示文昌方言没有不送气塞音[p]。另外,“b/m”表示某一方言点既有[b]也有[m],并且不区分这两个音位。将上述数据导入到Mega 5.2生物分子进化软件中进行分析。11个闽南方言点都具有这9个特征:[b]/[m]、[t]、[k]、[ 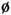 ]、[a]、[i]、[u]、[e]、[o],不存在任何差异,所以剔除这些无多样性的特征后,最终获得11个方言点共35个特征(大小为11×35)。 ]、[a]、[i]、[u]、[e]、[o],不存在任何差异,所以剔除这些无多样性的特征后,最终获得11个方言点共35个特征(大小为11×35)。本文采用P-distance距离模型来计算语言点之间的特征距离。该距离模型源于汉明距离(Hamming distance),主要是通过比较两种语言等长的特征序列,计算两条序列对应位置不同特征的个数,再除以特征总长度。该公式如下:  其中p代表两种语言的特征距离,n代表数据编码后的总长度, 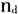 代表两个语言间的特征差异个数。例如语言 代表两个语言间的特征差异个数。例如语言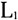 的有特征ABC,另一个语言 的有特征ABC,另一个语言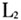 有特征BCDE,可以建立如下的表2: 有特征BCDE,可以建立如下的表2: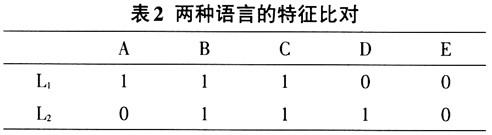 语言 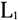 和 和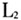 之间特征B、C是相同的,都是“1”,说明这特征是它们共有的,称为“双有”;特征E上都是“0”,称为“双无”,其他特征在数值上都不相同,根据上述公式这两个语言之间的距离是2/5。该计算方法主要用于二元编码,由于方法简单直观,所以受到众多学者的青睐(郑锦全1988;陆致极1992)。根据上述计算方法,可以获得11个方言点的距离矩阵(表3)。每一个单元格内的数字分别表示横轴和纵轴所示的代表点之间的差异,数值越大代表音系结构之间差异越大,数值越小代表差异越小。
(责任编辑:admin) 之间特征B、C是相同的,都是“1”,说明这特征是它们共有的,称为“双有”;特征E上都是“0”,称为“双无”,其他特征在数值上都不相同,根据上述公式这两个语言之间的距离是2/5。该计算方法主要用于二元编码,由于方法简单直观,所以受到众多学者的青睐(郑锦全1988;陆致极1992)。根据上述计算方法,可以获得11个方言点的距离矩阵(表3)。每一个单元格内的数字分别表示横轴和纵轴所示的代表点之间的差异,数值越大代表音系结构之间差异越大,数值越小代表差异越小。
(责任编辑:admin) |