|
根据核心一致对应和Swadesh 100核心词表,我们可以计算出亲属语言(方言)间核心同源词的比例,例如台语北部语群的三种语言之间核心同源词比例如下表所示: 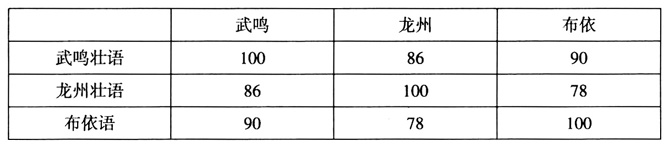 容易看出,布依语和武鸣壮语的同源词比例是最高的,说明这两个语言是最晚分化的。如果只有这三个语言,就可以根据上表给出谱系树:  但是随着同源语言的增多,从同源词比例表到谱系树的转换会成为一个相当复杂的数学问题,问题的核心在于怎样把由同源词比例构成的相似矩阵转换为谱系树。在关于物种或人种的亲缘关系研究中,也面临同样的问题。现在已经有了一些计算程序,比如Kitch,Fitch和Neighborhood。陈保亚、陈泽浩也开发了一种用于语言谱系分类的快速算法SFF(Simulated Force Field,模拟力场算法)。(26)由于这主要是一个数学问题,因此我们在此不多作讨论。 作为亲属语言(方言)谱系分类中使用最为广泛的两种方法,共享创新法和词源统计法各有得失。共享创新法的优点在于严格区分了创新和存古在谱系分类中的有效性,只有“独特的共享创新”才能作为谱系分类的论据;缺点则是共享创新法主要利用的是语言结构特征方面的创新,但共同的语音、语法特征的出现除了可能是语言分化的结果,还可能是来自平行演变和语言接触。后者的影响必须排除,但目前还没有有效的办法。此外,不同的特征常常会形成交叉现象,使得依据语言结构特征构建谱系树有不小的难度。而相比语言结构特征,Swadesh 100核心词更为稳定,在语言接触过程中不易借用,保持严格语音对应的核心同源词更不容易借用,这是在语言接触的实际调查中得出的经验事实。因此,我们更倾向于使用词源统计法作为亲属语言(方言)谱系分类的方法。但是词源统计法也有一些问题,我们提出严式词源统计法对过去的词源统计法在操作程序上严格加以限制。通过在严式词源统计法的基础上计算Swadesh 100核词表中亲属语言(方言)核心同源词的比例并将其转化为谱系树来反映亲属语言(方言)的亲缘关系,然后再参考共享创新。如果这两种办法能够相互支持,则谱系树的确信度比较高;如果有矛盾,则严式词源统计分析结果仍为基本依据,这时共同创新很可能是接触扩散或类型上平行发展的结果。正因为严式词源统计法先于共享创新法,所以亲属语言(方言)中核心同源词的确定必须首先建立语言(方言)间严格的语音对应,尽量剔除不同层次的借词,得到核心一致对应语素集,以保证词源统计法的可靠性。 核心同源词比例在谱系分类中的有效性还需要在今后的研究过程中作进一步的检验。目前来看,核心词原则在谱系分类中面临两个难点问题。一是选择那些词作为核心词。目前我们正在做的工作之一是调整核心词集,即根据大量田野调查结果,将前100个最不容易扩散的词作为核心词。另一个难点问题是如何判断核心一致对应语素集的语源性质。同源语言(方言)间的对应语素,也有可能是分化后通过接触横向接触的成果,特别是在接触情况复杂深刻的汉语方言中,即使是核心词也只是比较稳定,不易借用,而不是绝对不会借用。如何更有效地区分同源形成的对应和接触形成的对应还需要更多的工作。此外,如果在今后的研究中发现某些语音、语法特征比核心词更加稳定,就需要将这些特征作为谱系分类的标准。我们希望随着语言演变研究的不断发展和深入,我们所得到的谱系分类能够更接近语言分化的真实情况。 (责任编辑:admin) |