|
古籍书目数据库是指在统一的机读目录格式下按照相应的标准和规范加工而成,并最终以计算机网络系统形式向用户提供相关古籍数据资源检索的大型目录数据库。古籍书目数据库的建设适应了图书馆工作现代化的需要,是古籍文献揭示的一次重大飞跃。上世纪80年代以来,随着现代图书馆技术的发展,国内外图书馆相继开发建设了大量中文古籍书目数据库,对古籍书目数据库的标准与评价研究将有利于国内古籍书目数据库建设的顺利实施。 1古籍编目的计算机实践 随着计算机技术的发展,实现图书编目的计算机化逐渐成为图书馆管理自动化的一项重要工作。上世纪60年代,美国国会图书馆开始尝试馆藏图书书目的机读格式设计,于1965年推出M$ARC。70年代国际图书馆协会联合会(IFLA)推出UNIMARC。其后,诸多国家接受了UNIMARC磁带进行本国的书目数据库的建库工作。同期,中文古籍方面也开始了机读编目的尝试。1983年,美国加州研究图书馆组织(简称RLG)建立了一个自动化信息系统“美国研究图书馆信息网络(简称RLIN)”。80年代末,该组织提出一项计划,拟将中国清嘉庆以前的印本及抄稿本编制成计算机可读形式的中国古籍国际联合目录。[1]1991年9月“中国古籍国际联合目录”项目正式投入工作,共有18个图书馆参加了项目的工作。中国方面有北京大学、中国科学院、辽宁省图书馆、复旦大学、湖北省图书馆参加。 在台湾,为了推行中文图书编目的计算机化,1980年4月图书馆自动化作业规划委员会成立并积极开展中文图书编目的计算机化。1981年出版《中文图书机读编目格式》,1982年出版修订版。1983年出版《中国编目规则》。1984年出版《中国图书分类法(试用本)》《中文图书标题总目初稿》。在具体古籍编目实际方面,台湾国家图书馆自1981年起开始着手以电脑机读方式建立书目数据库,1984年2月编目作业过渡到全面自动化,采用《中国机读编目格式》《中国编目规则》,数据库中涉及古籍的数据量有汉学研究中心大陆出版品7257笔,中国善本古籍26396笔。[2]大陆地区的古籍计算机编目工作稍晚一些。上世纪80年代,东北师范大学古籍所开始进行文献书目微机处理的试验。1988年初,古籍所所长吴枫教授到日本调研后,看到日本国内各大学及研究机构已将文献书目输入了计算机,深感国内计算机古籍编目的意义重大,便开始了利用计算机收集和整理《中国现存古籍书目》的工作。[3]1984年国家图书馆安装了具有汉字信息处理功能的M-150H计算机系统,开始利用美国国会图书馆的机读目录磁带(LC-MARC)进行西文图书的辅助编目工作,并为国内用户提供专题和定题检索服务。1987年利用PDP11/73计算机进行普通中文图书的机读目录编目工作,随后建立了一批书目数据库。1995年,国家古籍整理出版规划小组决定筹建中国古籍书目数据库。[4]1995年下半年开始着手筹建普通古籍书目数据库的调研工作。1998年着手进行古籍书目数据库的建设。1999年编制了《古籍机读目录格式字段表》,其后,国家图书馆与北京大学共同研制了《古籍著录规则》(GB3792.7-87),编制了《汉语文古籍机读目录格式使用手册》等标准和规范。至2004年,馆藏善本古籍文献书目总库制作工作全部完成。实现了39万条数据的上网检索。【1】南京图书馆于1988年就开始购置计算机,进行古籍书目数据库建设的尝试。最初的工作是将馆藏10多万张古籍书目卡片输入到计算机中去,建成《馆藏古籍书目(草目)数据库》,数据库近20万条,包含馆藏古籍和影印、新印古籍。【2】1996年10月山东省图书馆选用“四库大汉字平台”和北京息洋电子信息技术研究所研制开发的GCS编目软件开始了古籍书目数据库的回溯建库工作,数据库的设置按《中国文献编目规则·古籍》、CNMARC执行,分类法采用《中国古籍善本书目》使用的四部分类法。【3】 2古籍书目数据库的标准 古籍书目数据库必须依照相应的标准和规范进行建设。秦淑贞在谈到什么是规范化的古籍书目数据库时认为:规范化的古籍书目数据库,是指在各种编目软件支持下做出的在格式、内容、标引依据以及字体等方面都按国家标准做出的一致的古籍书目数据库。要达到古籍书目数据库规范化必须做到六个统一。即:统一的机读目录格式;统一的著录规则;统一的分类法;统一的主题标引依据;统一的字库;古籍和普通图书统一建库。[5]其中古籍和普通图书统一建库的统一属于建库原则问题。因此,古籍书目数据库建设标准的选择应按照前五个方面来进行建库工作。 一是机读目录格式标准。统一标准的机读目录格式是建设和使用古籍书目数据库的必要前提。机读目录是一种以代码形式和特定格式结构记录在计算机存储载体上,可由计算机自动控制处理和编辑输出的书目信息目录格式。[6]目前,国内已建成古籍书目数据库所依据的机读目录格式,基本上都是在CNMARC的基础上做了适当修改和补充。《中国机读目录格式》中的题名与责任说明、版本说明等著录信息块,同样适合于标识古籍。不过,CNMARC处理的对象是现代文献,对于古籍却很难完全揭示。因此,出台适合古籍特征的《古籍机读目录格式》是十分必要的。《古籍机读目录格式》的制定应以CNMARC为蓝本,结合《古籍著录规则》,研究出一种标准的古籍机读目录格式。[7] 二是古籍著录规则标准。文献著录的标准化是文献资源共享的基础,统一而且行之有效的国家著录标准是建立书目数据库的根本条件。[8]我国于1987年颁布了《古籍著录规则》,该标准只是一个为手工著录而编订的著录标准。国内早期的古籍书目数据库建设多数参照了《古籍著录标准》为著录内容规范化的准则。《古籍著录规则》后经由全国情报文献工作标准化技术委员会第六分委会修订,并参考了《国际标准书目著录(古书)》。《古籍著录规则》(修订版)是结合我国古籍的特点,同时也考虑到计算机著录的要求而制定的。[9]上世纪90年代,随着古籍书目数据库的开发和建设,各馆藏单位在具体的数据库建设中发现《古籍著录规则》与国际通用的计算机识别兼容的著录规则还存在一定差距。因此,开发单位从实际出发也适当地做了调整。基于此,1996年由中国文献编目小组编撰了《中国文献编目规则》。《中国文献编目规则》较好地解决了这一问题。《中国文献编目规则》融合了各类型文献著录规则,确定了不同名称的参照关系,并通过标目法对文献题名和责任者名称予以规范控制,从而形成了适合我国汉语言文字特点,又与世界书目控制原则相吻合的一套完整、系统的编目规则。 三是古籍分类法标准。古籍书目数据库建设的一个重要目的就是向读者提供检索服务,其中分类检索就是一种重要的检索手段。“一个行之有效的分类法对古籍书目数据库的建设至关重要。”[10]因为建立统一的古籍书目数据库必须要有一个统一标准的古籍分类法。但是,由于古籍所具有的特殊性以及历史分类习惯难以更改,因此,至今尚未形成统一完善的古籍分类法。对于古籍书目数据库建设分类法的选择,目前图书馆界主要有3种意见,一种意见主张采用《中图法》,另一种意见主张采用《四部法》,第三种意见主张《中图法》和《四部法》相结合。《中图法》是中国图书分类的国家标准,是当前我国最有权威的图书分类法。《中图法》依照现代学科进行分类,既有利于读者的检索,也与国际标准分类相通。从读者检索习惯考虑,《四部法》已被广大文史工作者所熟知。但是,《四部法》的缺陷也十分明显。《四部法》不能与国际通用的机读目录数据库通融。因此,图书馆界多数学者倾向于《中图法》和《四部法》相结合,采用《中图法》第三版和《中国古籍总目分类表》作为古籍分类规范化的标准。 四是主题标引的标准。主题标引是保证机读目录质量的重要组成部分,也是开展文献检索的基础。[11]所谓主题标引“就是通过对文献内容的分析,把文献所论述的对象(或事物)概括起来,再使用规范化的词汇———主题词,将其按照一定的规范加以组织,使之成为检索语言的过程。”《中国分类主题词表》采用分类法与叙词表对照的检索语言。从内容到语义结构实现了分类语言与主题语言的兼容。[12]我国各级图书馆的编目主要是建立在《中图法》和《汉语主题词表》的基础上的,因此在机读数据库中使用《中国分类主题词表》不会打乱原有的图书编目体系。 五是统一字库的标准。《古籍著录规则》规定建立古籍机读目录必须使用原书字体。《中国文献编目规则·总则·著录用文字》规定:古籍著录一般按所著录文献本身的文字著录。由于古代文献年代久远,古籍中包含有大量生僻字、异体字、通假字以及手写字和避讳字,对计算机的文字输入是一个考验。已公布的汉字通用字符集如GB2313字符集(7478个字符)、BIG-5字符集(13868个字符)、GBK字符集(21885个字符)均不能完全处理古籍中汉字的复杂性。需要指出的是,由于GBK的编码体系不能通用于国际标准,如果采用它作为古籍数字化的字符集,会导致由于字符集的壁垒而使古籍书目数据库无法走向世界。因此,经过探索和实践,目前国内学术界在字符集的采用上已有主流看法:坚定不移地采用国际标准ISO/IEC 10646/Unicode字符集,该字符集拥有70195个字符,已成为国际通用的汉字输入平台。 3古籍书目数据库的评价 为了更直观地了解古籍书目数据库的理想标准,我们首先选取4个比较大型的古籍书目数据库进行比较: 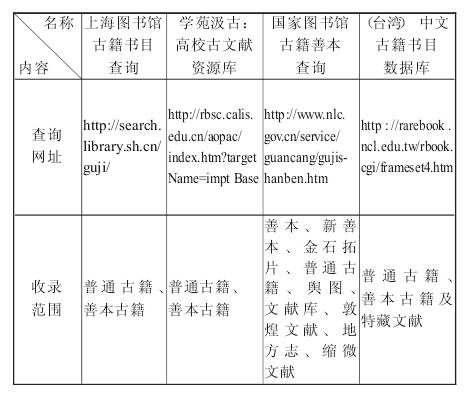 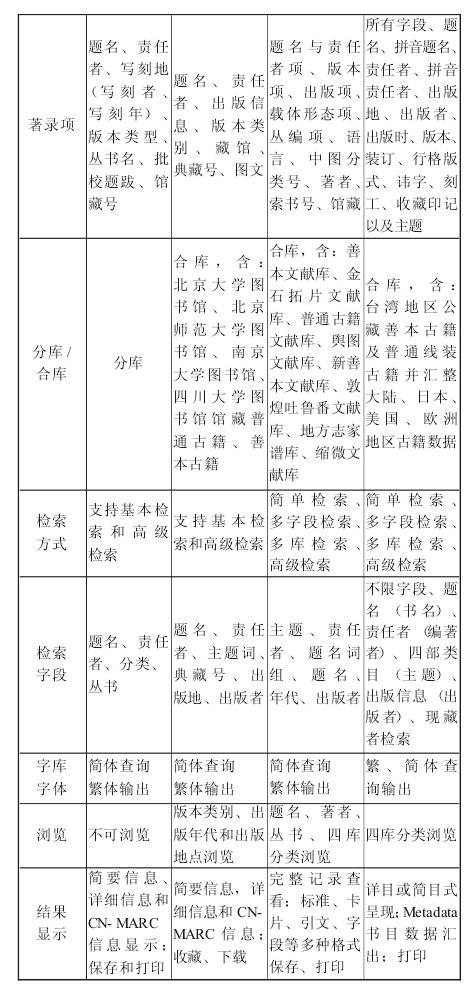 通过以上比较,我们可以清晰地看到,一个理想的古籍书目数据库应该是: 收录范围不能局限于普通古籍和善本古籍,而应更广泛地反映本馆的收藏,这包括善本古籍、新善本、金石拓片、普通古籍、舆图文献、敦煌文献、地方志、家谱、缩微文献以及其他更多馆藏文献。 著录项要尽可能多地显示文献信息,包括文献题名、责任者与责任方式、写刻出版地、出版者、出版年、版本类型、丛书名、批校题跋、馆藏号、索书号、分类以及图文对照显示。 分库还是合库是建设古籍书目数据库时争论的焦点。分库有利于文献信息集中揭示,比如早期古籍书目数据库建设时,多数将古籍库、地方志库、家谱库、地方文献库分别建库;合库则在数据库标准上难以统一。但实践证明合库是较为理想的选择。如“学苑汲古:高校古文献资源库”就采取了将北京大学图书馆、北京师范大学图书馆、南京大学图书馆、四川大学图书馆馆藏普通古籍、善本古籍并库检索;国家图书馆“古籍善本查询”也将善本文献库、金石拓片文献库、普通古籍文献库、舆图文献库、新善本文献库、敦煌吐鲁番文献库、地方志家谱库、缩微文献库进行合库检索;台湾“中文古籍书目数据库”更是整合了我国大陆、台湾地区及日本、美国和一些欧洲国家的古籍书目数据。 检索方式应支持基本检索和高级检索两种检索方式,用户可通过超链接方式进行选择。基本检索可支持选择单个字段输入单个检索词进行查询。高级检索可在多个字段中输入检索词,并对检索词进行布尔逻辑组配的检索方式。多个检索词默认的逻辑关系为AND,表示检索必须同时满足多个检索条件。也可以根据需要改变为OR。检索字段设置题名、责任者、主题词、典藏号、出版地、出版者、全面检索等尽可能多的检索途径,并能够提供某一检索形式如“包含”“前方一致”“精确匹配”进行检索。 字库字体应支持繁、简体查询和输出。大陆地区的古籍书目数据库多采用简体查询,繁体输出模式。台湾则更多采用繁体查询和输出。目前只有台湾地区国家图书馆“中文古籍书目数据库”提供繁、简体版查询接口,以两种字体进行输入检索。 浏览以题名、著者、丛书、四库分类浏览为佳。结果显示应以详目和简目式呈现;Metadata书目数据汇出;并能支持标准、卡片、引文、字段等多种格式保存和打印。 注释: 【1】张志清.中国国家图书馆古籍书目数据库的建设与共享[C]//台北:古籍联合目录数据库合作建置第三次研讨会,2004. 【2】马宁.南京图书馆藏古籍编目和数字化工作情况简介[C]//台北:古籍联合目录数据库合作建置第三次研讨会,2004. 【3】李西宁.山东省图书馆古籍建库情况[C]//台北:古籍联合目录数据库合作建置第三次研讨会,2004. [参考文献] [1](美)艾思仁.中国古籍与21世纪的研究图书馆[J].津图学刊,1996(4):8-13. [2]郑恒雄.中文书目资料库在台湾的建立与发展[J].图书馆工作与研究,1995(5):3-10. [3]刘乾先,王彩云.文献书目微机处理研究报告———利用计算机整理及检索现存古籍书目[J].古籍整理研究学刊,1991(2):15-17. [4]杨健.$C$ALIS中文古籍联机合作编目的缘起与进展[J].图书馆理论与实践,2006(5):54-56. [5]秦淑贞.如何建立规范化的古籍书目数据库[J].现代图书情报技术,1999(2):39-41,48. [6]韦衣昶.普通图书机读书目数据[M].北京:北京图书馆出版社,2003:8-10. [7]姚秀敏.古籍书目数据库建设存在的问题及措施[J].江西图书馆学刊,2002(4):20-21. [8]王运堂,李勇慧.关于善本古籍书目数据库建设的回顾与思考[J].中国图书馆学报,1999(2):47-50. [9]魏书菊,王杏允.浅谈古籍书目数据库建设的前期准备[J].大学图书情报学刊,2002(2):47-48. [10]刘劼.古籍书目数据库建设刍议[J].图书馆理论与实践,1998(4):27-28. [11]冯泽泗.机读目录的结构编制与应用[M].成都:成都科技大学出版社,1992:150. [12]贺定安.《中国分类主题词表》一体化标引方法研究[J].中国图书馆学报,1995(6):74-77. [作者简介]毛建军,男,新乡学院中文系讲师,博士,主要从事古籍整理与电子文献研究,已发表学术论文52篇。 (新乡学院 中文系,河南 新乡 453000) 原载:《图书馆理论与实践》2009年第6期 (责任编辑:admin) |