|
平行语料中句子对齐并非都是一对一的关系,因此句子对齐并非一件容易的事。经过二十多年的研究,句子对齐处理技术现在已经相对成熟。句子对齐方法主要有3种:1)基于句长的方法(Brown et al.1991;Gale & Church1991);2)基于双语词汇互译信息的方法(Kay &Roscheisen1993;Ma2006);3)句长和双语词汇互译信息混合的方法(Wu1994;Tan & Nagao1995;Moore2002)。由于西方语言和东方语言差异较大,基于句长的句子对齐方法不适合英汉汉英句子对齐处理。实践也证明,军事领域的英语文本与汉语文本的长度比值跨度太大,通常在0.8至7.5之间,用基于句长的方法来实现句子对齐效果欠佳。基于双语词汇互译信息的句子对齐方法还可以细分为基于双语词典的句子对齐方法和基于语料库词汇统计的句子对齐方法。使用双语词典进行句子对齐时,如果词典的词汇量小,词汇互译信息一般不足,常常得不到满意的结果;当英汉词典足够大时,基于词典的句子对齐系统可以找到比较充足的词汇互译信息,从而更好地实现句子对齐。而在使用基于语料库词汇统计方法获取词汇互译信息时,其算法必须基于一定规模的双语平行语料库。当语料不足,词汇的重现频率过低时,词汇互译信息会严重不足,从而不能有效支持句子对齐算法。在军事英汉汉英平行语料库建设初期,有时在一个子领域只能找到零星的几篇英汉对译短文。这种情况下,基于大容量英汉词典实现句子对齐是最佳选择。 为检验语料不足时基于统计与基于词典的句子对齐方法之间的差异,我们用基于语料库词汇统计的Hunalign(Varga et al.2005)以及基于词典的Champollion(Ma2006)对一段汉英军事平行语料进行句子对齐测试。该语料中英语部分有210句,4040个单词;汉语部分有161句,6613个汉字。句子对齐结果见表1。 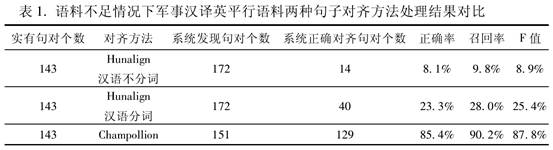 表1的统计数据显示,在语料不足的情况下,基于语料库词汇统计的Hunalign句子对齐效果明显好于基于词典的Champollion,说明基于词典的句子对齐方法效果好。 军事英汉汉英平行语料库建设起步阶段主要以实现句子对齐为主。句子对齐的平行语料是效用最大的平行语料(Ma2006:489):进行短语、词汇对齐前一般需要首先实现句子对齐;机辅翻译的翻译记忆库建设只要求达到句子级对齐;基于实例的机器翻译需要大量双语句对提供翻译实例;基于统计的机器翻译需要足量的双语句对作为训练语料,从中获得翻译模型。在语料库翻译学中,句子对齐平行语料库通常也是进一步获得其他翻译知识的基础。 基于对句子对齐方法的理解和对目前军事英汉汉英平行语料库建设使用情况的了解,我们自主开发了一个有图形界面的基于词典的英汉汉英平行语料句子对齐综合处理平台。该平台能够实现英汉混合文本自动拆分和机辅段落对齐,在句子对齐过程中自动实现英汉句子边界识别、英语形态还原、汉语分词,在句子对齐结果中保留段落标记。平台还提供句子对齐所用的英汉词典的管理功能。 (责任编辑:admin) |