构式搭配分析法:用法·优势·意义——以英语way构式为例
http://www.newdu.com 2025/11/02 10:11:22 未知 王欢 林正军 参加讨论
摘 要:语料库语言学为计算词项和构式搭配关系提供了越来越多的方法。本文以英语way构式为例,介绍构式搭配分析法的主要功能和使用中的常见问题。同时,通过比较构式搭配分析法、对数比值比、互信息值和卡方值对way构式的计算分析,阐明其在理论与方法上的优势和选择这种方法的理据。这对精准认识、熟练掌握和广泛推广构式搭配分析法具有一定价值。 关键词:构式语法;构式搭配分析;构式搭配强度;相关性测量 作者简介:王欢,东北师范大学外国语学院博士研究生,吉林农业大学外国语学院副教授,研究方向:认知语言学、构式语法、二语习得;林正军,东北师范大学外国语学院教授,博士生导师,研究方向:认知语言学、功能语言学、应用语言学。 基金:国家社会科学基金重点项目“认知教学语法的构建与应用研究”(项目编号:13AYY010)的阶段性研究成果。 1. 引言 大数据时代,语料库语言学的应用研究越来越广泛,研究方法也呈日趋多元的趋势。探寻词项和构式间关系的方法有很多,如“互信息值(MI,MI3)、Z值(Z-score)、T值(T-score) 、Log-log值、卡方值(χ2)、对数拟然比(Log-likelihood ratio)、Dice系数等”(梁茂成、李文中、许家金 2010:94),以及对数比值比(log10 of odds ratio)(Schmid & Küchenhoff 2013)和ΔP值(Ellis & Ferreira-junior 2009)等。各种方法都有其优势与不足(Wiechmann 2008),那些不考虑总频率的单纯频率方法本身的可信度值得怀疑, 这就迫切需要在理论上对关联强度进行重新界定与方法的探寻。Gries et al.(2004)提出的构式搭配分析法 (Collostructional Analysis,CA)成为这一领域具有划时代意义的重要研究成果。CA是一种相关性测量(Association Measure)方法(Gries 2015:507),通过测量特定构式与出现在该构式空位中的词项之间的关联强度,即“构式搭配强度”(Gries et al. 2010:62),研究词项与构式共现关系(colligation)。在上述研究方法中,每种方法均有各自优点,相比而言,CA在词项和结构的计算方法上复杂度高,但为何仍是一种被普遍认可的研究方法呢?本文以英语way构式为例,阐述使用CA的理据性。首先,阐明CA的基本功能及操作问题;其次,分别使用CA、对数比值比、互信息值、卡方值方法对其进行计算分析, 厘清使用CA方法的优势,以及在理论、方法论和实践上的意义。 2. 基本操作和常见问题 2.1 基本操作 Gries等提出的CA是一系列研究方法,包含共现词素分析法(Collexeme Analysis)、显著共现词素分析法(Distinctive Collexeme Analysis)以及互为变化共现词素分析法 (Co-varying Collexeme Analysis) 。其中,共现词素分析法是其它两种方法的基础,所以本文以共现词素分析法为代表,阐述其用法、优势与意义。 共现词素分析法的基本操作一般包含4个步骤:1)检索相关词项(如,词、短语或构式);2)计算构式搭配强度;3)排序计算结果;4)分析前1—50词项1的功能和语义(Gries 2015:508)。搭配强度的计算方法如表1所示: 表1. 构式搭配强度列联表 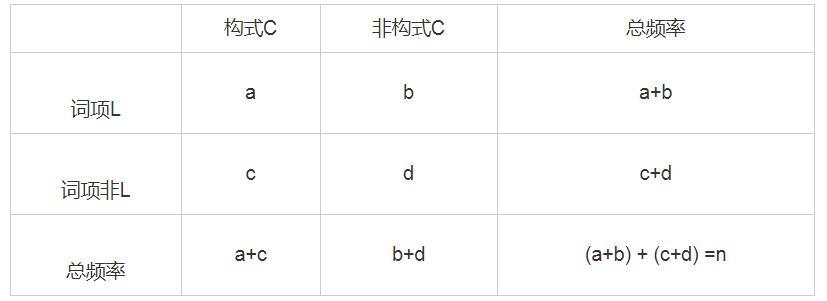 1) a为词项L在构式C中的频率; 2) b为词项L在其它构式(排除构式C)中的频率,其值为a+b(词项L在语料库中的总频率)减去a; 3) c为构式C出现在其它词项(排除词项L)中的频率,其值等于a+c(构式C总频率)减去a; 4) d为其它词项在其它构式中的频率,其值等于a+b+c+d减去a+b+c2。 再将a,b,c,d四个值代入公式1,进行费歇尔精确检验 (Fisher-Yates Exact Test,FYE),得到构式搭配强度p值。 公式1 (Gries et al. 2005:647) : 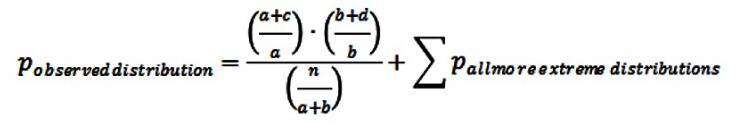 2.2 常见操作问题 CA全面考虑词项在既定构式中的频率(a值),词项在其它构式中的频率(b值),其它词项在既定构式中的频率(c值),以及其它词项在其它构式中的频率(d值),因此,大大提升了计算搭配强度的科学性。然而,由于CA比单纯频率的方法,如条件概率(reliance和attraction3)的方法,更加复杂(Gries 2015:524),因此需要对计算构式搭配强度过程中的几个问题进行梳理。 2.2.1 d值的确定 Bybee (2010) 以及Schmid & Küchenhoff (2013) 认为d值表示其它词项在其它构式中的频率,但由于一个小句可含有多个构式,并且每个小句中所含构式的数量和既定词项产生构式的数量都不确定,因此语料库的构式总数也就难以计算,这就使d值难以确定。事实上,与相关性分析有关的研究都会遇到上述问题,“常见的解决方法是选择所研究现象的最接近粒度 (level of granularity) ”(Gries 2015:523),也就是采用近似值方法,CA则以论元构式中动词数量为基础计算d值2。 2.2.2 搭配强度的计算 Gries基于R语言开发出Coll.analysis 3.2a软件,用于计算构式搭配强度。通过该软件, 输入a值、a+b值、a+c值和语料库的总频率, 即可得到与构式搭配分析相关的计算值,包含期望值(exp.freq)、吸引或排斥的相关关系(relation)、双向的ΔP值(ΔPC→W和ΔPW→C),以及构式搭配强度(coll.strength)。利用该软件,可极大简化构式搭配强度的计算,并增强其可及性。 以英语way构式为例,笔者对COCA语料库中2010—2015年的way构式进行提取,得到类符数1899、形符数5250(a+c值)。首先,对检索结果进行除噪,除去be,know,lose和have这些非动态的表达(于翠红2015),余下way构式的形符数为4876,并将数据按动词条目进行合并,得到动词类符数为553个,计算每个动词的形符数,如动词find的形符数为488(a值),研究选取形符频率大于3的动词,共106个;然后,检索每个动词在语料库中的总频率,如find的总频率为124011(a+b值);最后,将上述两个数据find[488,124011]4,加上构式的形符总数4876和语料库的总频率123108235输入Coll.analysis 3.2a软件,并选默认的FYE来计算搭配强度等值,详见表2。 表2. 英语way构式搭配强度计算表 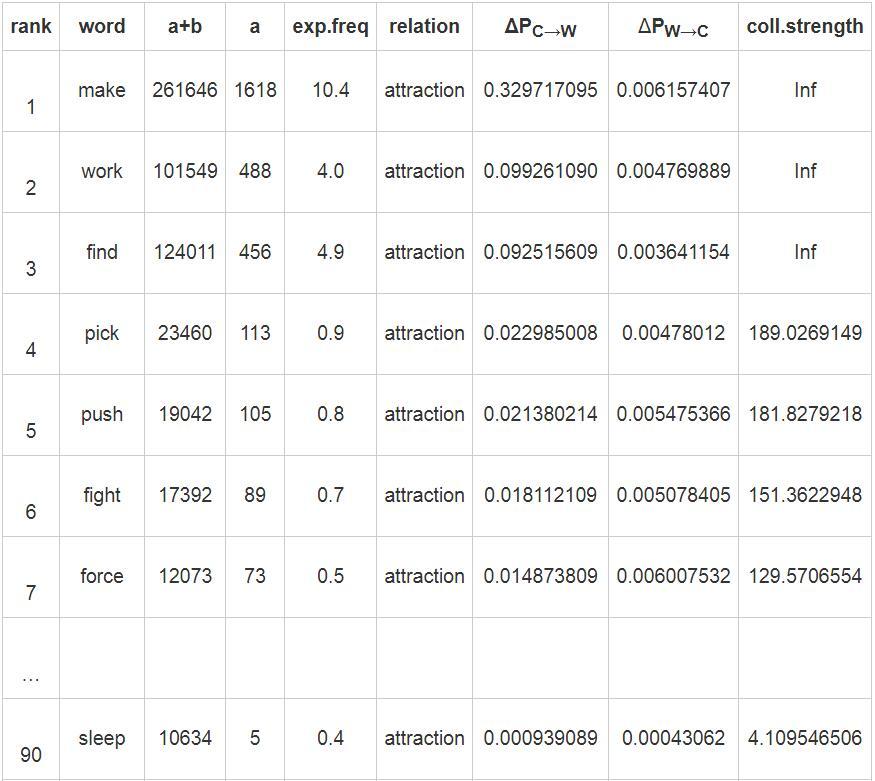 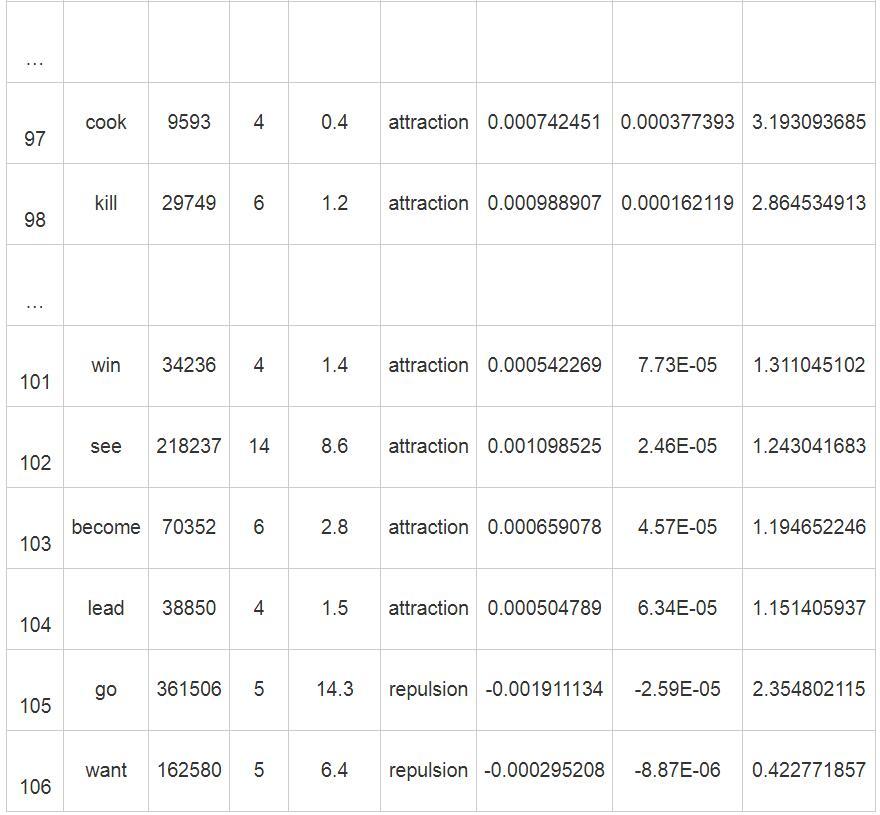 2.2.3 Log对数判定 CA使用p值测度构式搭配强度,其值介于0和1之间,然而,当其值落于0到0.05区间时,在统计学上才具有意义。结合大数定律等统计学理论可知,当p值越趋近于0值,即正无限小时, 其统计学上的构式搭配强度越显著。CA采用-log10p (简称P值) 来反映其搭配的显著性强度。结合表2,当force的p值为2.6875E-130时,其相应的P值为129.5706554,同理当cook的p值为0.000641071时,其P值为3.193093685,可见,前者>后者。又因,当以p=0.055作为拒绝域时,计算P值为1.301,换言之,当P值>1.301时,其构式搭配强度就具有统计学上的显著性。结合表2,see(排位102),become(排位103)和lead(排位104)因不具有统计学上的显著性,故需排除。 2.2.4 吸引和排斥的判定 CA的明显优势就是利用期望值对构式的准入动词进行吸引和排斥的判定。具体期望值的计算公式为: 公式2(Gries 2016:180):  结合公式2,我们可以确定其吸引或是排斥关系。动词出现的频率(a值)和期望值需进行比较分析,如果前者大于后者称之为“吸引”,反之为“排斥”。结合表2,以动词lead (排位104) 和go (排位105) 为例, 其排位差不多,但为何一个为吸引,一个为排斥?下面是对lead和go期望值的分析: pexpection (lead) = (4+4872) * (38850) /123108235=1.539<4,由于a值(4)大于期望值pexpection(1.539),所以呈正向吸引关系; pexpection (go) = (5+4871) * (361506) /123108235=14.32>5,因其a值(5)小于其期望值pexpection(14.32),故呈排斥关系。 因此,结合表2,动词go(排位105)和want(排位106)与way构式呈排斥关系,即使前者搭配强度值(2.355)大于1.301。 3. 构式搭配分析法的优势 互信息值、对数比值比、卡方值和CA是比较常见的探寻词项和构式间搭配关系的方法。CA采用的FYE方法要优于其它统计方法(Wiechmann 2008),因其不违反分布假设(Ellis & Ferreira-Junior 2009:198),也无需考虑样本容量,就能确定词项和构式的搭配关系是吸引还是排斥,因此,CA方法较上述其它方法具有理论优势。为了验证其优势,本研究采用搭配分析工具Coll.analysis (3.2a),分别选择FYE、MI、χ2和log10 of odds ratio, 各自计算way构式与动词间的关联强度,计算结果如表3所示: 表3. 基于不同测度方法的way构式准入动词前10位关联强度比较 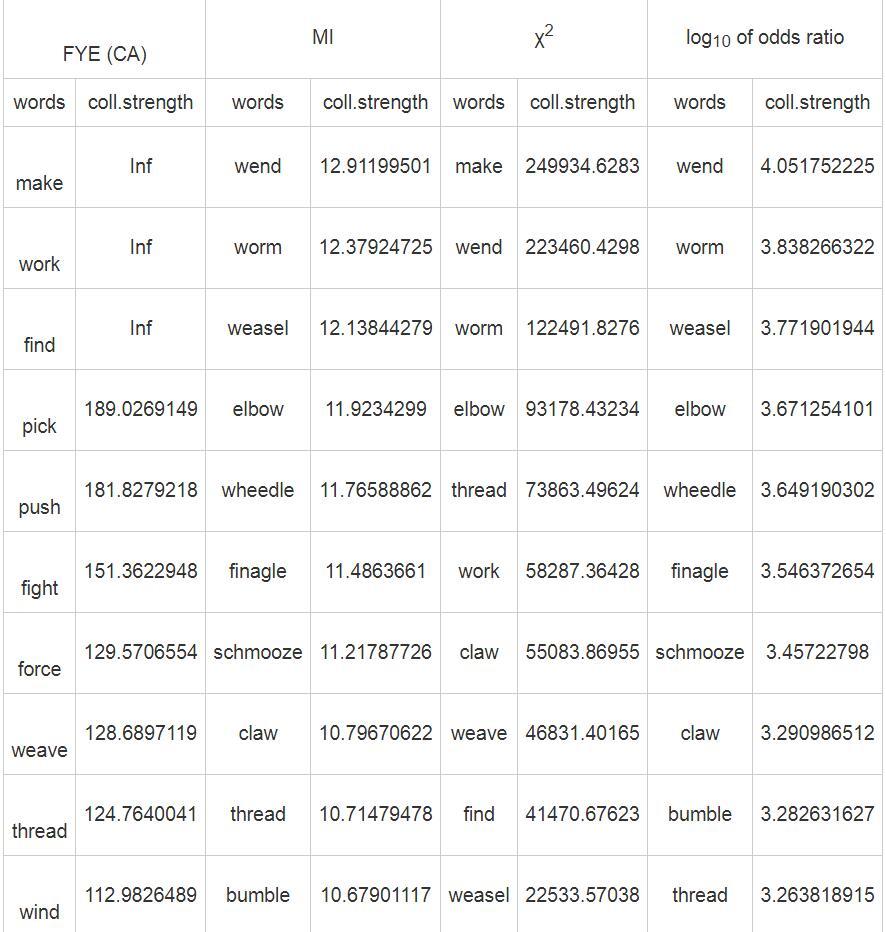 结合表3排序,发现FYE计算结果要明显好于其它方法。在FYE计算结果排序中,显而易见,前10位动词均符合常识性构式认知。另外,这10个动词的规约化性质都很强,通过检索权威词典,发现这些动词的way构式已成为固定词条,如:push one's way (牛津英语大词典 2004:2412) ;weave your way(柯林斯COBUILD英语学习词典 2000:1249) ;thread your way through/into sth.etc.(朗文当代高级英语辞典 2009:2413) 等。因此,结合词典条目验证, 采用FYE析出的way构式准入动词具有科学性;而采用MI和log10 of odds ratio方法得出的前10个动词中均排除含make的way构式最典型的动词。Way构式具有比较强的能产性(谷峪、林正军 2017),其在COCA语料库里的形符数为4876,动词make在way构式中出现的频率为1618,约占1/3,可见排除make有失科学性和准确性。而χ2虽包含make,work等类典型动词,但仍排除一些规约化很强的高频词,如表2中pick(113),push(105)等。 从上述计算结果中,我们发现FYE搭配强度要好于其它方法,以下结合英语way构式的计算结果(见表2、3),剖析其深层次原因。 3.1 理论基础优势 “主流语言学理论从传统的规定主义,经过了结构主义、转换—生成语法等‘基于规则'的语言理论,进入了以认知语言学为主要代表的‘基于用法'的语言理论时代”(武和平、王晶 2016:1) 。CA是基于使用的理论(usage-based theory),承认构式是形式和意义或功能的结合体,以及动词意义和构式意义相融合和压制的复杂关系,并以使用为基础对构式重新进行定义。首先,CA考虑类符频率。认知语言学和语料库的研究表明,音系、形态或句法模式的能产性源于类符频率,这是因为“类符多的构式比类符少的构式更容易出现在新项目中”(Goldberg2006:99),换言之,一个构式含有的类符越多、普遍性越强,学习者就更容易将其延伸到新项目中。CA的第一步就是检索出相关词项,way构式的动词类符数为553,可见其能产性极强;其次,考虑形符频率,如way构式的形符数量为4876,动词make在构式中的形符数为1618,形符量越大,固化(entrenchment)和规约性则越强,make必然成为最类典型的动词,当然也是构式搭配强度最强的动词;再次,这种方法还考虑了类符和形符频率的分布情况。Goldberg (2008) 认为,在语言学习过程中,中心的、低变化的类别和偏向输入的内容更容易被习得,可见类符、形符分布的重要性。若某一词项在其它构式中高频出现,这说明该词项与当前构式的搭配强度应减弱,同理,其它词项若在本构式中高频出现,也说明本构式对该词项的吸引不具有唯一性,其搭配强度也应减弱。以go[5,361506]和sleep[5,10634]为例(见表2),都在way构式中出现了5次,前者与构式排斥,而后者与构式吸引,究其原因,就是go在其它构式中的形符比sleep高。CA方法反映了认知规律要包含多个维度特征,如类符、形符、类符形符比,因此,基于多个维度的CA优势性明显。 另外,词项在语料库中的齐普夫分布也为CA提供了强认知基础。Goldberg(2006:5)对构式的定义为:“任何的语言构型 (形式和意义的结合体) 都可以作为构式,只要其形式或意义的某些方面不能在其组成成分或已有的其它构式中推导出来,那么它就是一个新构式。另外,某些能被完全预测出来的语言构型,只要有足够的出现频率,也可作为构式储存于记忆中。”语料库的齐普夫分布显示,形符频率越高、类符频率越小,熵值越小。这种熵值的分布使许多研究有了认知基础,也给构式提供了新的定义。Gries(2012:505)提出了以“使用”或以“例证”为基础(usage/exemplar based)的构式定义:“当一种富含信息的形式和至少一种功能特点的汇合被注意到后,一个特殊的构式就能出现。”这更证明了Goldberg对足够频率的论证,如果一个或多个形式和一个或多个功能特点的汇合变得足够的偏向,并能减少维度分布的不确定性,那么这个频率就能足够支撑产生一个新构式。 3.2 统计方法优势 CA是一种基于相关性测量的分析方法,多数采用FYE作为统计方法,在测度单向关系时使用ΔP值方法。其方法上具有如下优势: 3.2.1 CA方法更具适应性 假设检验方法必须要对原始数据分布做前期假设,这就存在一些无法避免的问题。以χ2为例,从统计学理论上讲,其使用时必须假设语言现象是严格符合随机分布规律,即符合正态分布,但其违背了语言规律中的一个基本事实,那就是“语言绝不、从不、永远不可能随机”(Kilgarriff 2005:263)。结合表3,由于χ2要求语言数据符合随机分布,所以其对动词的相关性排序难以反映真实情况。 语言数据存在稀疏性特征,而MI方法在稀疏数据处理上具有敏感性,高估低频词的搭配关系(Kilgarriff 2001)。据表3可见,MI方法中排名前10的动词均为低频词,例如:wend[29, 95], worm[23, 109], weasel[5, 28],表现出异常高的关联强度,可见这种方法面对语言的稀疏问题难以适应。 根据log10 of odds ratio的计算方法,结合表1, 其值为 (a/b) / (c/d) ,是一个效用值 (Schmid & Küchenhoff 2013)。在表3中,与MI方法比较可知,除bumble和thread两个词顺序互换外,log10 of odds ratio排序前10的动词与MI排序前10的动词一致,这也验证了该方法和MI方法存在同样问题(Gries 2012:491),即因动词搭配的稀疏性导致低频词异常高的关联强度。 综上所述,从统计学视角来看,由于CA无需对所分析的样本数据进行分布假设(Gries 2016:204),又因FYE被认为更适合于参数检验、非对称检验,可用于识别具有非独立关系的词语配对,且不容易被语料库中所体现出具有偏态和稀疏的语言自然特性所影响。综上对比可知,CA成为当前最适合研究词项和构式关系的方法之一。 3.2.2 搭配强度可反映多维信息 CA并不否定与语言习得和固化相关的单纯频率,相反,其可以凸显单纯频率的作用,这种方法强调多维频率信息。P值与单纯频率相比也更加优化,单纯频率体现的影响是线性的,如果一个词的词频是另一个的两倍,那么重要性和固化等指标也是两倍。然而,学习、认知、记忆上的规律并不是线性的。语言发展是非线性的,“浮现属性是非线性相互作用的结果,而不是部分属性的总和”(韦晓保 2012:19) 。因此,单纯频率的线性数学特征无法反映认知过程常识。由于考虑了词项在构式中的频率和词项在语料库中的总频率,P值并非如频率一样体现线性功能,而是体现词项在构式中的功能变化、词项和构式总体频率变化,因此符合认知曲线的标准。 另外,P值更体现动词与构式关系的固化和规约化。例如,在reliance值3都是0.3时,3:10与300:1000两者间存在差异性,第二组数据更体现固化和规约化,FYE对后一组数据的结果更加敏感, 能检验测量两者的差异性。以way构式为例, 表3中FYE方法析出的前10位都是固化和规约化强的动词, 因其均出现在词典的固定条目中。 P值不是效应量, 但可以反映样本总量、样本变体和效应量的总和 (Gries 2015:520) 。P值能反映出词项与构式的关系到底是吸引还是排斥, 程度如何, 这就是效应量。P值是使频率更加显著, 而非降低频率的影响力, 即样本总量和变体不大的情况下, 强效应影响P值。以way构式为例, 表2中a, a+b等值的比值与P值间存在正向对应关系。因此, 使用P值, 其数值反映了相关性 (association) 、显著性 (significance) 和频率 (frequency) , 具有可信度。 3.2.3 可计算单向关系 构式可以吸引词项,反之词项亦可吸引构式,而CA采用的FYE对于吸引方向不敏感。为了弥补这种缺陷, CA借用Ellis & Ferreira-Junior (2009) 提出的ΔP方法6, 能够区分这两种单向关系,并依据表1中a, b, c, d四个值计算ΔP值。  ΔPconstruction→word是指构式C对词项L的吸引减去其它构式对词项L的吸引;ΔPword→construction是指词项L到构式C中的比率减去构式C对其它词项的吸引。以表2体现的way构式和其准入动词搭配关系为例, ΔPC→W为way构式对动词的吸引强度, 而ΔPW→C为动词对way构式的吸引强度。 4. 构式搭配分析法的意义 CA研究词项和构式的关系, “与以前的方法相比, CA能将这种关系描述的更精确透彻” (Perek 2015:89) 。 4.1 方法论意义 CA在统计方法上的优势非常明显, 更强调了共现的绝对频率基础上的相对频率, 且不否定反映固化、规约和类典型的基本频率, 强调多维频率信息。Gries (2010) 用实验的方法证明了在说话者产出和理解任务方面CA要优于单纯频率的方法。FYE是一种精确检验而不是渐进检验, 不设定分布假设, 其对低频和偏向频率更起作用, 效果要比MI, χ2和log10 of odds ratio都好。通常p值 (小于0.05) 有两种意义, 一方面它反映了效应量 (effect size) , 因为CA对期望值的设定, p值能反映出词项与构式的关系到底是吸引还是排斥, 及其程度如何, 这就是效应量。另一方面, 它反映了样本量, 也就是说, 如果我们处理的样本更大, 值就更大。 4.2 理论意义 CA除了统计方法较为科学外, 其理论价值也很突出, 对语言现象的观察、描写和解释都更为详尽, 对语言理论和模型的构建也有重要意义。 1) 观察充分性。 这种方法不仅观察既定词项在既定构式中的频率 (a值) , 还观察了既定词项在其它构式中的频率 (b值) , 其它构式在既定词项中的频率 (c值) 以及其它词项在其它构式的频率 (d值) 。由于对a, b, c, d四个值进行详细观察, 能够充分了解语言的分布特性, 而对语言进行多维度的观察是详尽描写语言的基础。 2) 描写充分性。 这种方法优于内省式分析,语料库最基本的概念就是统计假设。词项的分布与功能和语义相关,以频率为基础的分布分析可以显示出功能上的聚类,CA可以进行语义聚类的分析, 通过FYE探寻搭配强度前50的动词,分析其语义特征,排行最高的动词意义与构式意义相融最好,继而可以推出构式意义。例如,陈佳 (2015) 用CA研究结构COME/GO+ADJ,发现其类典型意义是一种“结果义”。只有对构式意义进行充分描写,才能客观解释各种语言现象。 3) 解释充分性。 CA考虑了词项和构式类符、形符、类符形符比,充分地解释了第一语言、第二语言构式的习得现象;此外,CA对于构式的历时研究对解释语言的语法化现象有重要的意义 (Hilpert 2006b:251) 。 CA对于语言理论和模型的构建也有重要意义。Stefanowitsch & Gries (2003) 认为研究动词和语法构式的相互联系是对构式理论的支撑。同时,Gries (2012) 以“使用”或“例证”为基础对构式进行了定义, 丰富了对构式语法的理论构建。 4.3 应用意义 通过Coll.analysis 3.2a软件计算构式搭配强度, 可以使数据处理得到简化, 使其可及性增强。CA已经被应用于英语 (田臻, 等 2015) 、荷兰语 (Colleman 2009) 、瑞典语 (Hilpert 2006a) 、俄语 (Sch?nefeld 2006) 和汉语 (王红卫 2017) 等研究;除了主要分析论元构式之外, CA被用于时和体 (tense & aspect) (Wulff et al. 2009) 、语态 (voice) (Gries & Stefanowitsch 2004) 、语气和情态 (mood & modality) (Stefanowitsch & Gries 2003) 的研究;CA还可应用于语言习得 (Ellis & Fernando-Junior 2009;詹宏伟、周颖洁 2012) 、语言的共时、历时研究 (Hilpert 2006b;黄莹 2016) , 语言的心理学研究 (Wiechmann 2008) 。此外, 这种方法当然也对词典编纂有非常重要的意义。 5. 结语 CA作为一种新兴的研究词项与构式间关系的方法,在国外呈现多语言、多层次、多领域等蓬勃发展趋势,构式语法各个分支的研究都可从中受益。为明晰CA方法的基本操作与使用中的常见问题,本文以way构式为例,对其做了详细介绍。同时,为探析CA方法的优势,本文深入对比构式搭配分析法、对数比值比、互信息值和卡方值,对way构式的计算与分析。研究结果表明:CA是一种有效的研究词项和构式关系的语料库研究方法,在理论基础、统计方法等诸多方面均具有优势, 此种方法的应用能够提高对语言的观察充分性、描写充分性和解释充分性。 参考文献 [1] Bybee,J.Language,Usage and Cognition[M].Cambridge:Cambridge University Press,2010. [2] Colleman,T.The semantic range of the Dutch double object construction[J].Constructions & Frames,2009(2):190-220. [3] Ellis,N.& F.Ferreira-junior.Constructions and their acquisition:Islands and the distinctiveness of their occupancy[J].Annual Review of Cognitive Linguistics,2009(1):187-220. [4] Goldberg,A.Constructions at Work[M].Oxford:Oxford University Press,2006. [5] Goldberg,A.& D.Casenhiser.Construction learning and Second Language Acquisition[A].In P.Robinson & N.Ellis(eds.).Handbook of Cognitive Linguistics and Second Language Acquisition[C].New York and London:Routledge,2008:197-215. [6] Gries,S.& A.Stefanowitsch.Extending collostructional analysis:A corpus-based perspective on ‘alternations'[J].International Journal of Corpus Linguistics,2004(1):97-129. [7] Gries,S.,B.Hampe & D.Sch?nefeld.Converging evidence:Bringing together experimental and corpus data on the association of verbs and constructions[J].Cognitive Linguistics,2005(4):635-676. [8] Gries,S.,Hampe,B.& D.Sch?nefeld.Converging evidence II:More on the association of verbs and constructions[A].In S.Rice & J.Newman (eds.) .Empirical and Experimental Methods in Cognitive/Functional Research[C].Stanford,CA:CSLI,2010:59-72. [9] Gries,S.Frequencies,probabilities, and association measures in usage-/exemplar-based linguistics:Some necessary clarifications[J].Studies in Language,2012(3):477-510. [10]Gries,S.More(old and new)misunderstandings of collostructional analysis:On Schmid and Küchenhoff (2013) [J].Cognitive Linguistics,2015(3):505-536. [11]Gries,S.Ten Lectures on Quantitative Approaches in Cognitive Linguistics[M].Beijing:Foreign Language Teaching and Research Press,2016. [12]Hilpert,M.A synchronic perspective on the grammaticalization of Swedish future constructions[J].Nordic Journal of Linguistics,2006a(2):151-172. [13]Hilpert,M.Distinctive collexeme analysis and diachrony[J].Corpus Linguistics & Linguistic Theory,2006b(2):243-256. [14]Kilgarriff,A.Comparing corpora[J].International Journal of Corpus Linguistics,2001(1):97-133. [15]Kilgarriff,A.Language is never,ever,ever,random[J].Corpus Linguistics & Linguistic Theory,2005(2):263-276. [16]Perek,F.Argument Structure in Usage-based Construction Grammar[M].Amsterdam/Philadelphia:John Benjamins Publishing Company,2015. [17]Schmid,H.& H.Küchenhoff.Collostructional analysis and other ways of measuring lexicogrammatical attraction:Theoretical premises,practical problems and cognitive underpinnings[J].Cognitive Linguistics,2013(3):531-577. [18]Sch?nefeld,D.From conceptualization to linguistic expression:Where languages diversify[A].In S.Gries & A.Stefanowitsch(eds.).Corpora in Cognitive Linguistics:Corpus-Based Approaches to Syntax and Lexis[C].Berlin & New York:Mouton de Gruyter,2006:297-344. [19]Stefanowitsch,A.& S.Gries.Collostructions:Investigating the interaction of words and constructions[J].Cognitive Linguistics,2003(2):209-243. [20]Wiechmann,D.On the computation of collostruction strength:Testing measures of association as expressions of lexical bias[J].Corpus Linguistics and Linguistic Theory,2008(2):253-290. [21]Wulff,S.,Ellis,N.R?mer,U.& K.Bardovi-Harlig.The acquisition of tense-aspect:Converging evidence from corpora and telicity ratings[J].Modern Language Journal,2009(3):354-369. [22]陈佳.基于语料库的“COME/GO+形容词”构式搭配关联强度与构式范畴化关系研究[J].解放军外国语学院学报,2015(3):23-30. [23]谷峪,林正军.WAY构式高能产性的范畴化网络扩展机制研究[J].西安外国语大学学报,2017(1):17-22. [24]黄莹.强化词“absolutely”搭配构式语义趋向与语义韵的历时变异[J].西安外国语大学学报,2016(2):39-43. [25]柯林斯COBUILD英语学习词典[Z].上海:上海外语教育出版社,2000. [26]朗文当代高级英语辞典(第4版)[Z].北京:外语教学与研究出版社,2009. [27]梁茂成,李文中,许家金.语料库应用教程[M].外语教学与研究出版社,2010. [28]牛津英语大词典[Z].上海:上海外语教育出版社,2004. [29]田臻,黄妮,汪晗.词汇体、语法体与there存现构式原型性的共变[J].外国语,2015(5):33-43. [30]王红卫.汉语双及物构式和动词关联度的实证研究[J].外语研究,2017(4):22-26,82. [31]韦晓保.第二语言习得理论研究的新视角:D-C-C模式[J].外语界,2012(6):18-27. [32]武和平,王晶.“基于用法”的语言观及语法教学中的三对关系[J].语言教学与研究,2016(3):1-10. [33]于翠红.基于英汉平行语料的way构式汉语再词汇化模式研究[J].外语教学与研究,2015(1):42-54,159-160. [34]詹宏伟,周颖洁.构式联接:基于语料库的双宾构式定量分析[J].西安外国语大学学报,2012(4):56-61,66.基金项目 注释 1这是一个比较宽泛的值,只要能说明问题,可取50以下的值。 2利用Coll.analysis3.2a软件,该d值无需具体算出,只需输入语料库总频率。软件访问网址:http://www.linguistics.ucsb.edu/faculty/stgries/teaching/groningen. 3attraction和reliance的计算公式如下,其中a,b,c值与表1中相一致。 4这种格式在全文中,第一个数值为动词在way构式中出现的频率,第二个数值为当该词词性为动词时,在语料库中出现的总频率,数据均从2010-2015年COCA语料库中检索获得。 5亦可选取p=0.001作为拒绝域,此时,当P>3才有意义。 6ΔP值输入相关数据,采用Coll.analysis 3.2a可直接算出,表2中包含way构式与动词的双向关系。 (责任编辑:admin) |
- 上一篇:新兴网络语言“A到VP”格式探析
- 下一篇:句法何以构词